Kafka topic partitions are replicated across brokers. Data loss happens when the brokers where replicas are located are unavailable or have fully failed. The worst scenario — and where is no much to do — is when all the brokers fail; then no remediation is possible. Replication allows to increase redundancy so this scenarios is less likely to happen.
The following scenarios show different trade-offs that could increase the risk of lossing data:
Choose reusing infrastructure (cost) at the risk of impacting multiple components
For brokers to be less likely to fail together are usually placed in different locations, e.g. physical servers, racks, data-centers, availability zones, regions.
If, for cost effectiveness, brokers end up in shared locations, then the chances to fail together may increase.
For instance all brokers could end up in the same backing physical server. If the physical server fails, then all brokers will fail.
Same happen with any other location (e.g. Availability zones), and this is what leads to topologies across regions.
Be careful about shared resources.
Choose throughput at the risk of lossing data
Replicas follow a 1-leader/many-followers model, where writes only happen at the leader, and the leader waits for the followers to be up-to-date before ack back to the producer — only when the producer is configured with ack=all.
If the producer has a lower durability guaranty than acks=all — 1 or 0 —, then produce request’s lifecycle will be much faster — no waiting for replicas.
Latency and throughput — from producer’s perspective — are heavely impacted when acks is reduced from all to 1 or 0.
If data is acknowledged only when written to 1 replica, then we risk lossing data as it is only confirmed to be in 1 node.
One can even end up ack’ng on 1 replica without acks != all:
- (Obviously) if partition only have 1 replica.
- If
min.insync.replicasis equal to 1 and followers are unavailable — i.e. out of the ISR.
Remember: reducing acks doesn’t really reduce the overall latency, and acks=all is now the default.
Choose availability in the face of potential data loss
In the previous tradeoffs we are at the risk of data loss or data being unavailable — but you don’t know unless you go to the broker and check :)
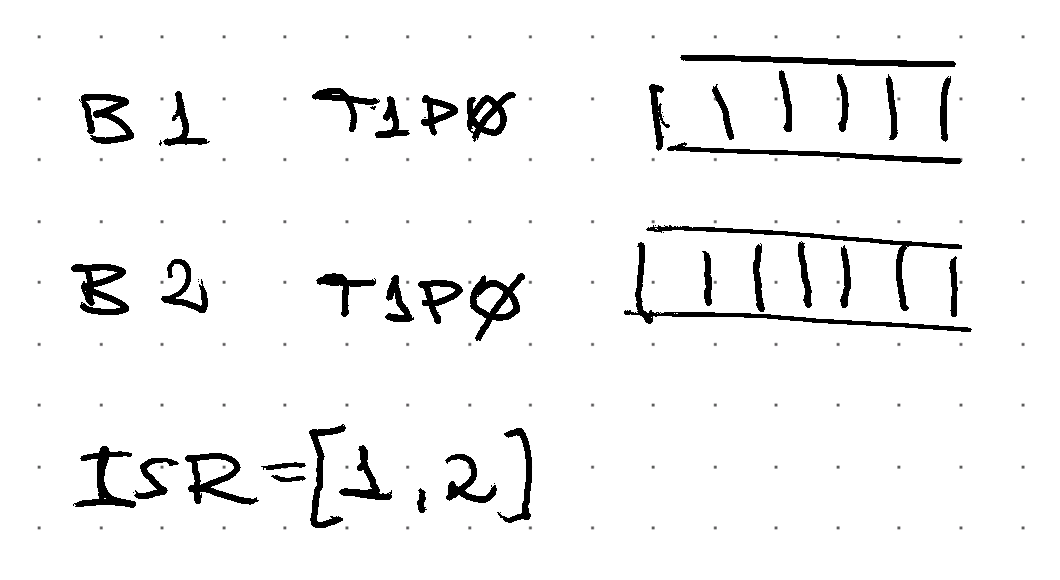
Happy path, all replicas are in-sync
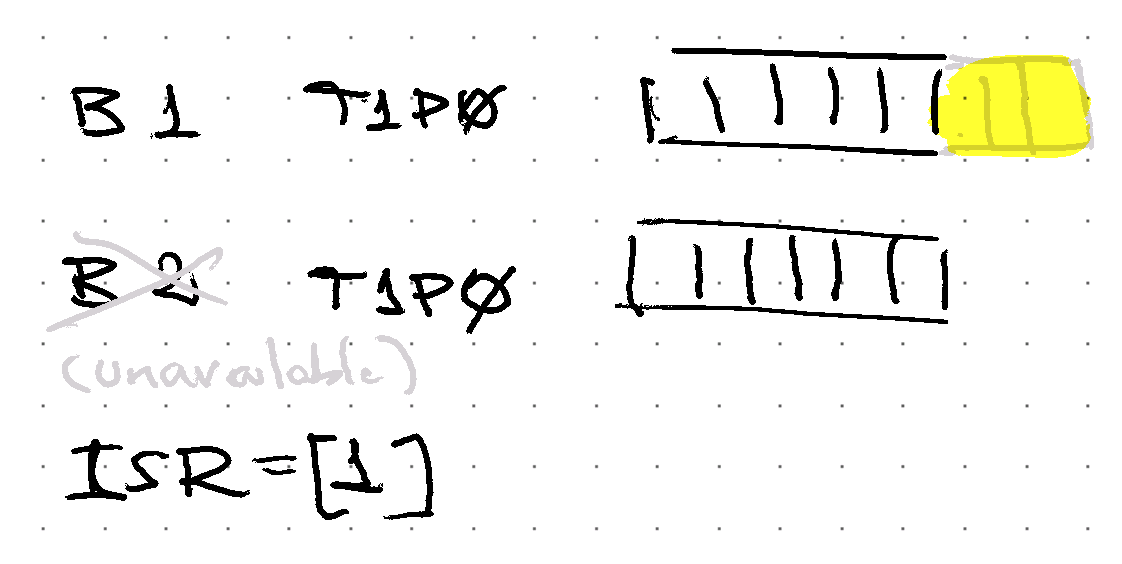
Some replicas are down, data is written on the replicas available…
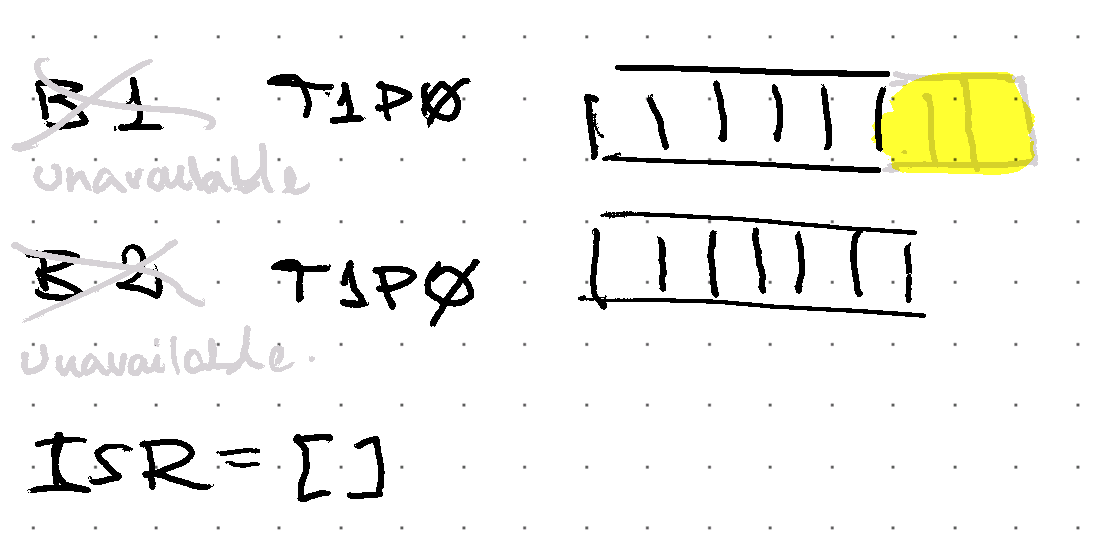
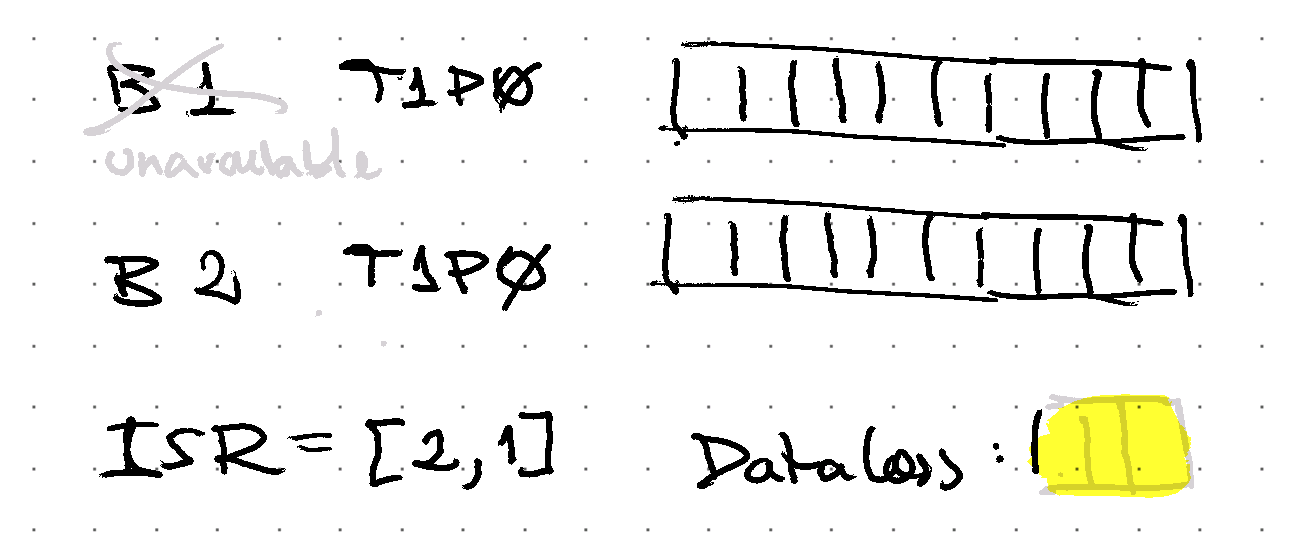
Sudenly, the replicas with the latest data are not available any more…
Under this scenario, there is a chance that non-insync replicas (i.e. not a member of the latest ISR set) are available then operators can choose: is it OK to stay unavailable until an insync replica is back? or should we choose to risk loosing data and allow the non-insync replicas to be the leader and accept writes?
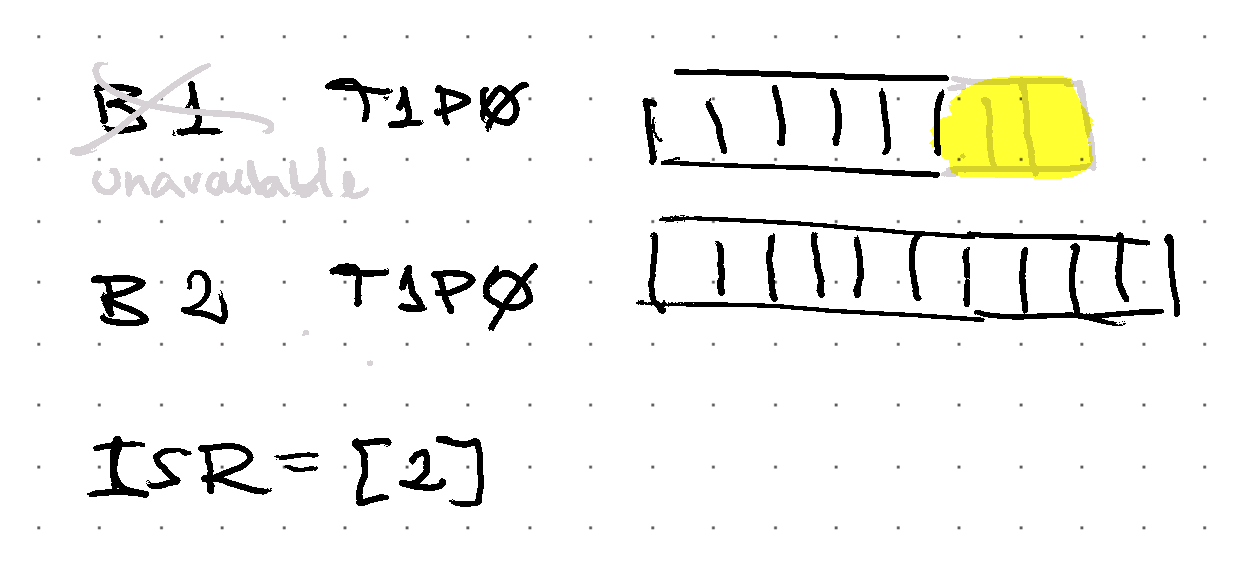
With some bad (or good?) luck, the replicas start to come back, but they include the replicas that do not contain the latest records…
unclean.leader.election.enable is the flag that enables non-insync replicas to be the leader.
If a non-insync replica is taking leadership, then data that is not synchronized will be lost:
when replicas are back and they have data that is not synchronized, then that data is truncated out down to the latest known synchronized message (i.e. high watermark).
Make sure to balance these trade-offs according to your needs 🙌.