Things to remember:
- Topic replication factor is not enough to guarantee fault-tolerance. If
min.insync.replicasis not defined i.e. 1, then data could potentially be lost. acks=allwill force replica leader to wait for all brokers in the ISR, not only themin.insync.replicas.- If replicas available are equal to minimum ISR, then the topic partitions are at the edge of losing availability. If one broker becomes unavailable (e.g. restarting), then producers will fail to write data.
- Topic configuration is inherited from the server. If broker configuration changes, it affects the existing topics. Keep the topic defaults, unless it needs to be different than broker default for easier maintenance.
When writing data on Kafka topics, it’s often required for this data to be replicated across multiple brokers and enforce this replication as part of the writing process.
This is enforced by the Producer when setting acks=all.
min.insync.replicas define the minimum number of replicas required to acknowledge back to producers.
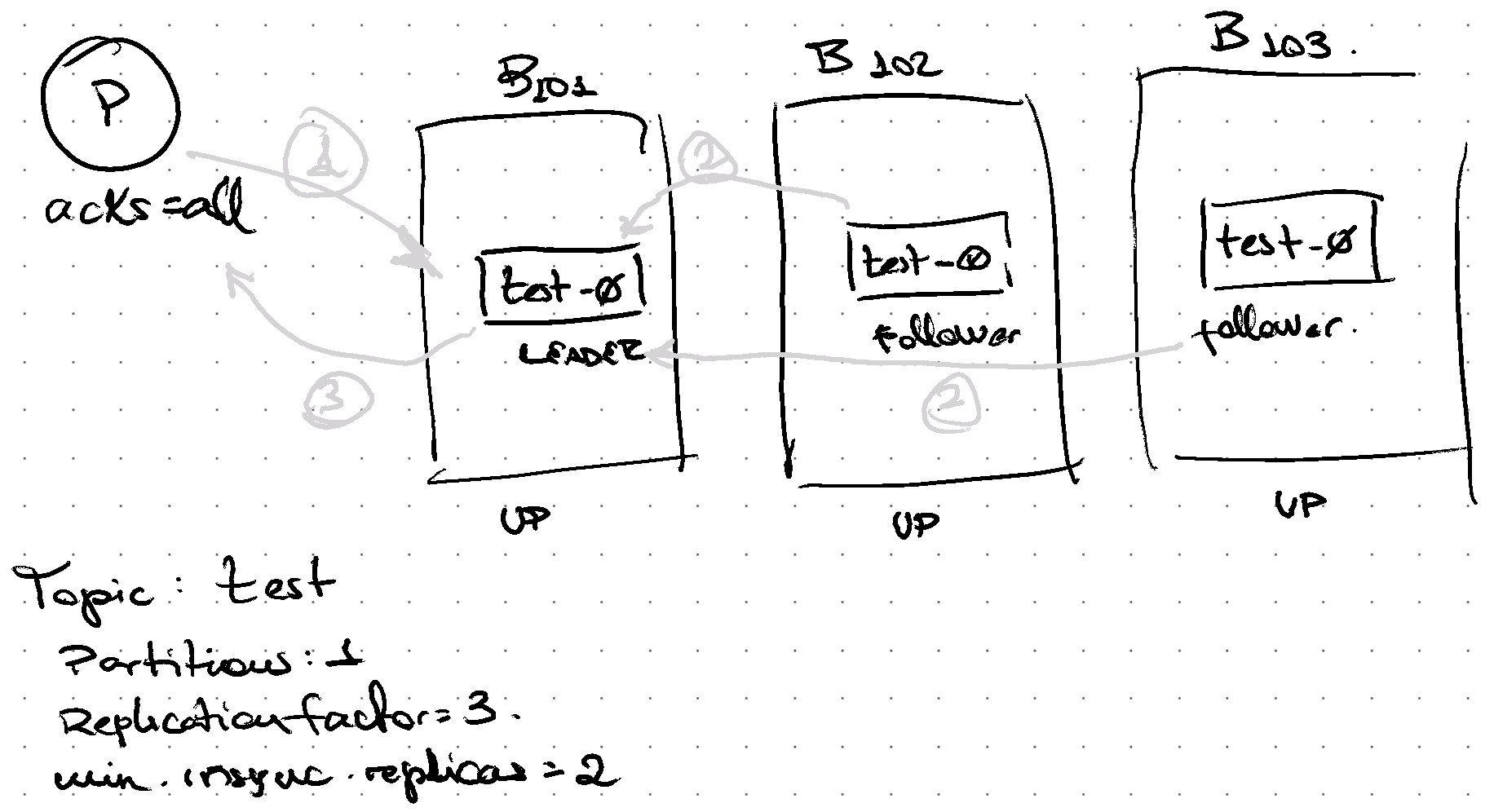
When all replicas are in-sync:
- Producer sends a request and Broker stores locally.
- Replica followers fetch changes increasing high-watermark (last offset acked by all replicas)
- Broker sends response back with acknowledge to the Producer.
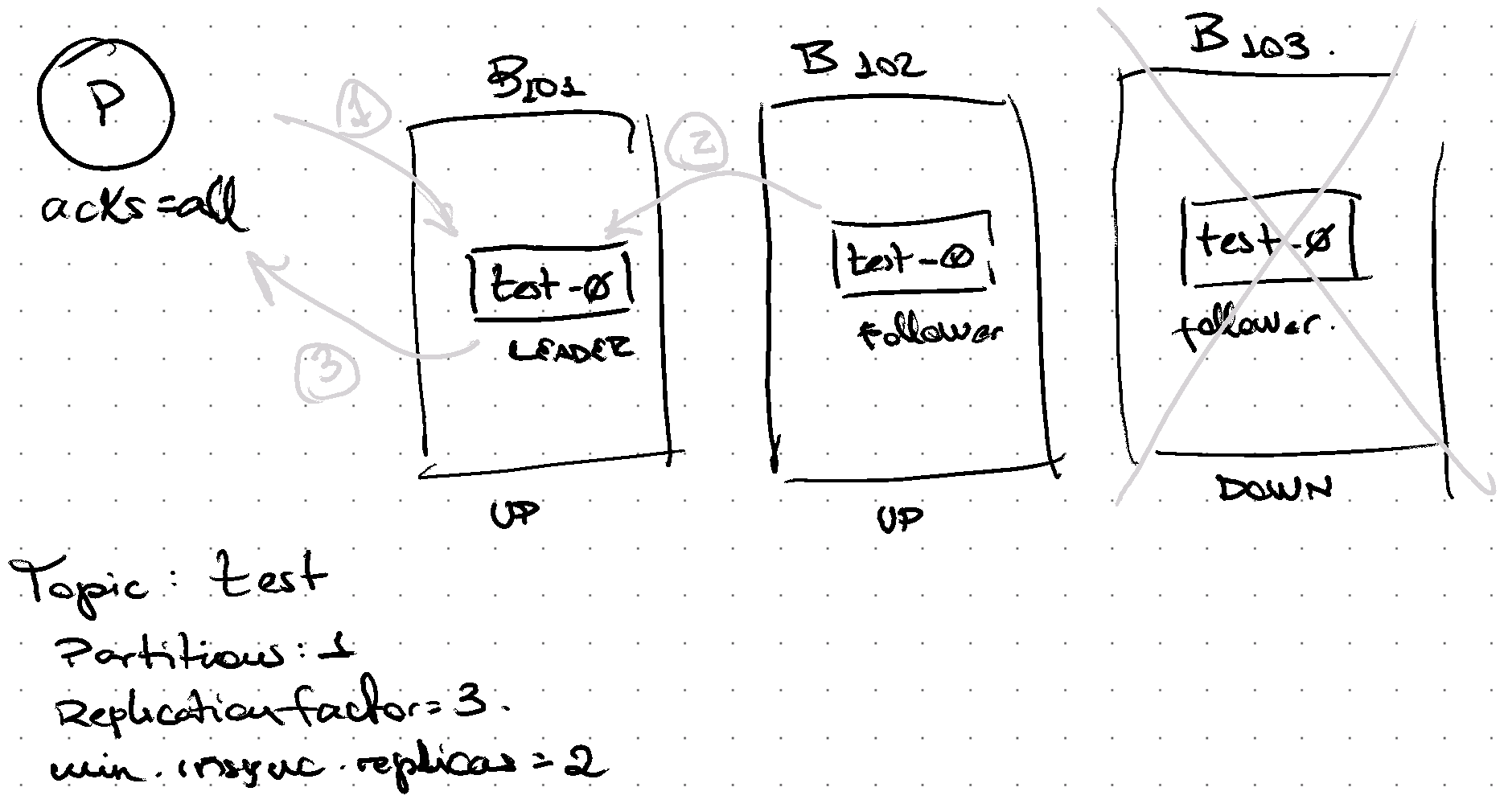
When 1 out of 3 replicas is out of sync or down, same procedure.
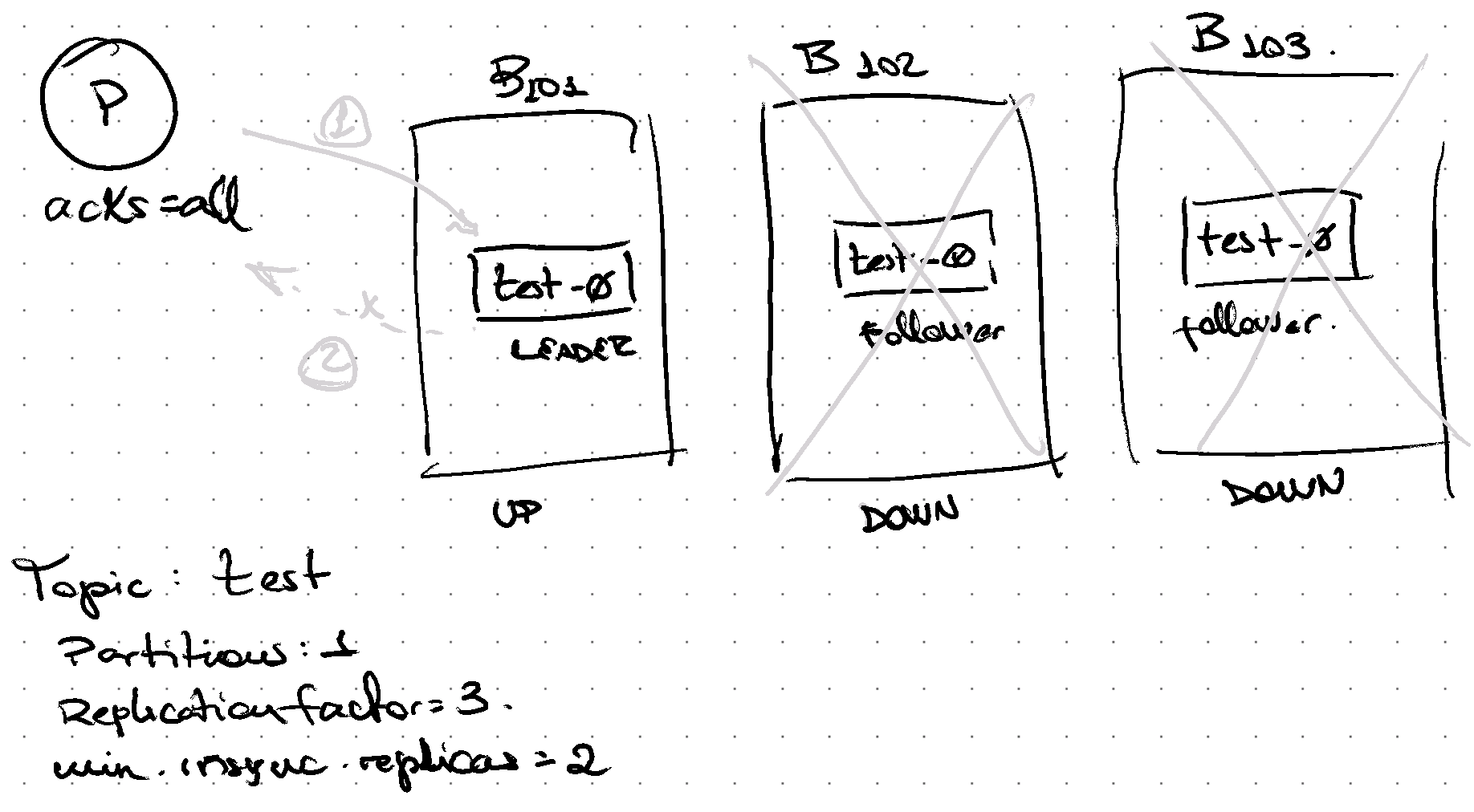
When 2 out of 3 replicas are out of sync or down, there are not enough replicas to ack Producer. Request fails.
By default min.insync.replicas is 1, therefore if only 1 replica is part of the in-sync-replica (ISR) set, writing will be successful.
This is usually considered a risky configuration as there could be failure scenarios where data is stored only in 1 broker and if that broker is lost (e.g. disk failure), then data is lost as it’s not replicated yet.
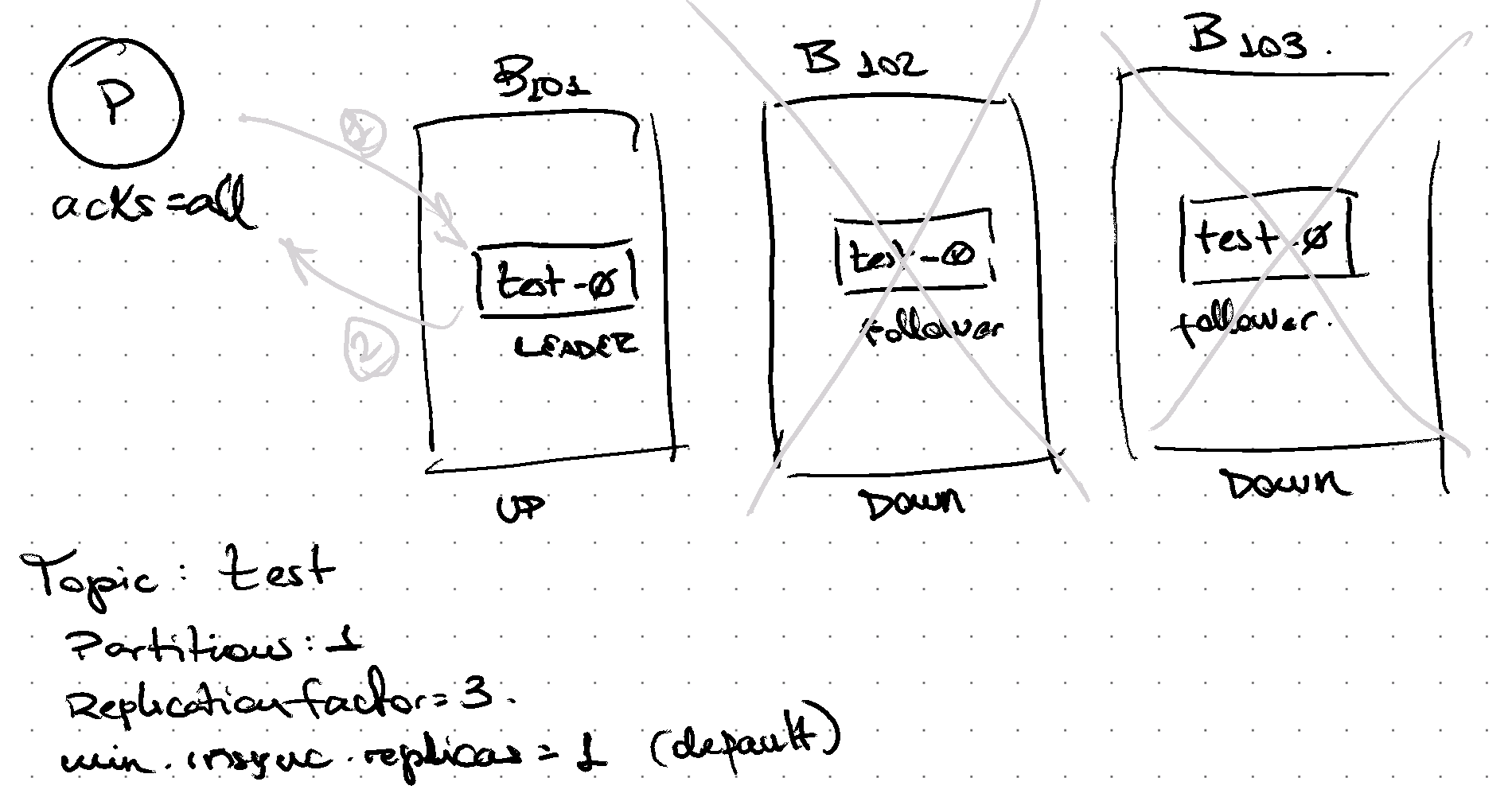
Data will be written to only one partition
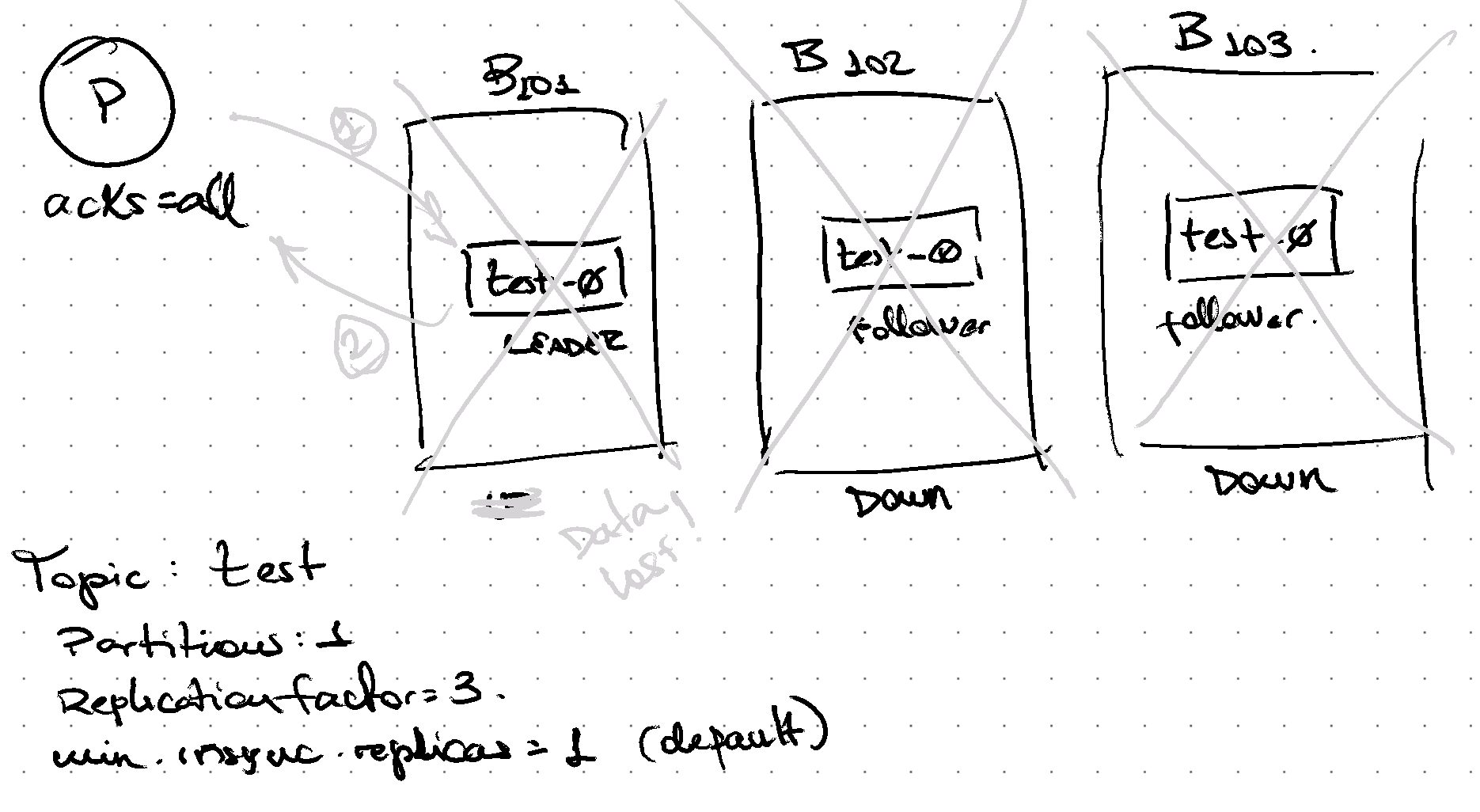
If data is not replicated yet, and broker fails, data will be lost.
I used to confuse the purpose of this configuration as a way to minimize the number of replicas that need to acknowledge a message before replying to clients in any scenario.
For instance, I thought that if replication factor (RF) is 4, and min.isr is 2, then only 2 replicas are required to acknowledge messages back to clients at any time.
Similar confusion spotted here.
So, be mindful about the replication factor. All the replicas take part of the writing process when acks=all. The more replicas per topic partitions, the higher the changes for the replication to be slower — the more network and disk used as well.
Choose a number of replicas that guarantee data is replicated across data centers (e.g. across racks, cloud availability zones, regions, etc.)
For instance, Confluent Cloud uses RF=3 and min.isr=2.
This is the algorithm at Partition.scala class that implements this validation:
def appendRecordsToLeader(records: MemoryRecords, origin: AppendOrigin, requiredAcks: Int,
requestLocal: RequestLocal): LogAppendInfo = {
val (info, leaderHWIncremented) = inReadLock(leaderIsrUpdateLock) {
leaderLogIfLocal match {
case Some(leaderLog) =>
val minIsr = leaderLog.config.minInSyncReplicas
val inSyncSize = isrState.isr.size
// Avoid writing to leader if there are not enough insync replicas to make it safe
if (inSyncSize < minIsr && requiredAcks == -1) {
throw new NotEnoughReplicasException(s"The size of the current ISR ${isrState.isr} " +
s"is insufficient to satisfy the min.isr requirement of $minIsr for partition $topicPartition")
}
val info = leaderLog.appendAsLeader(records, leaderEpoch = this.leaderEpoch, origin,
interBrokerProtocolVersion, requestLocal)
// we may need to increment high watermark since ISR could be down to 1
(info, maybeIncrementLeaderHW(leaderLog))
case None =>
throw new NotLeaderOrFollowerException("Leader not local for partition %s on broker %d"
.format(topicPartition, localBrokerId))
}
}
info.copy(leaderHwChange = if (leaderHWIncremented) LeaderHwChange.Increased else LeaderHwChange.Same)
}