I have been lucky to attend Kafka Summit London this year (thanks, Aiven!) and wanted to share some notes on topics that caught my attention from the sessions I was able to attend:
Keynote by Confluent
Confluent made some exciting announcements on their cloud offering:
- Managed Debezium Connectors; just reaffirming how well-positioned this project is as the de-factor CDC platform
- A bunch of Flink-related features – and no mention (IIRC) of Kafka Streams or KSQL
- Data Portal and the ability to have more human-driven workflows to give access to Kafka resources (similar to Klaw)
But most importantly, the inclusion of Apache Iceberg into their strategy, promising bi-directional (or “multi-modal” as Jack Vanlightly shared in his blog) realizing the “Topic to Table duality” paradigm in a different frontier (i.e., the Analytical Estate).



However, I did miss some more OSS-oriented content at the keynote. I still remember 2020’s keynote. It was all about OSS Kafka. It was lovely—but times change.
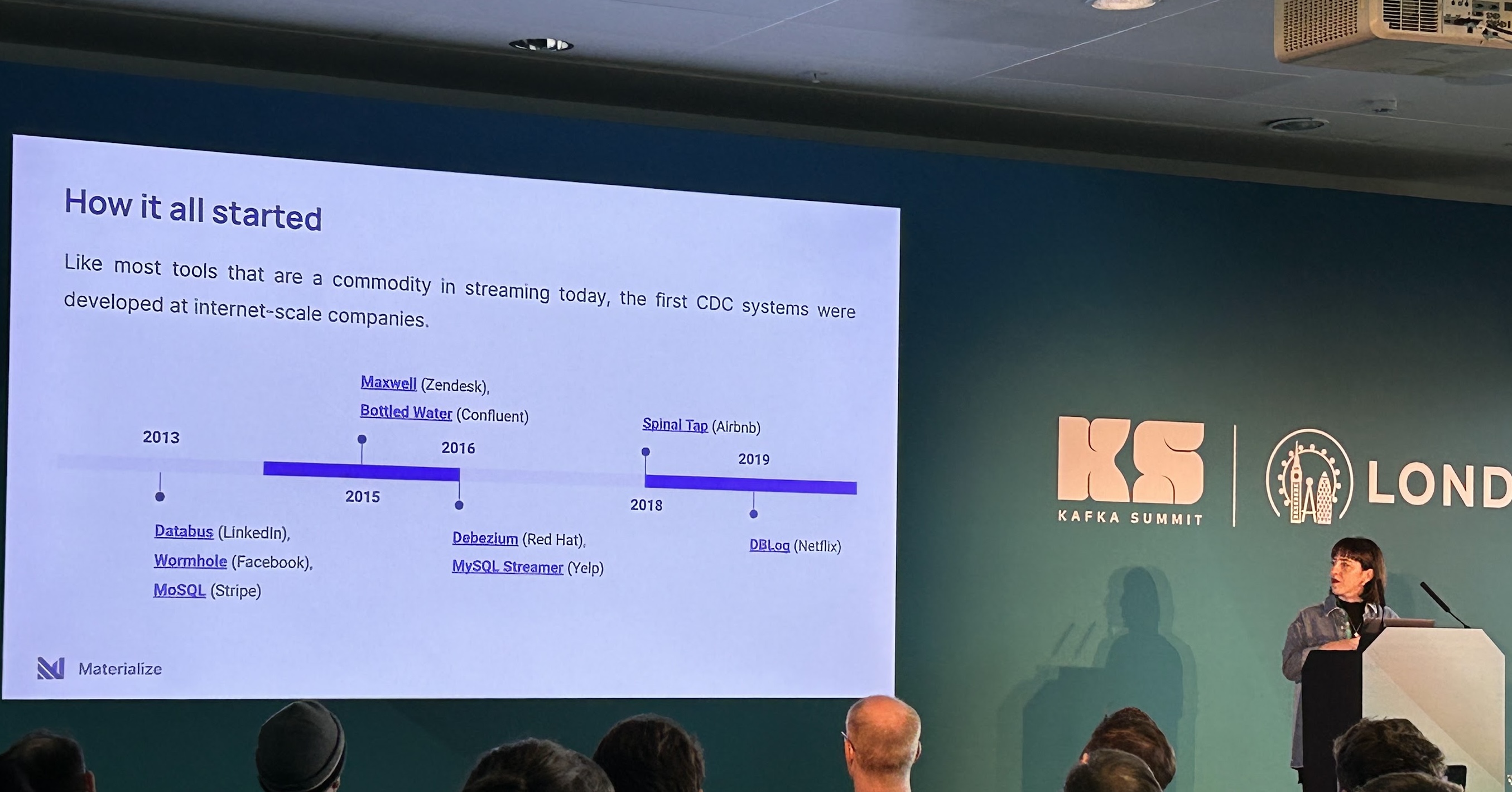
Lightning Talk on Debezium by Marta Paes from Materialize
I liked this short talk on Debezium’s history and how/why some vendors choose to build on top—while others (like Materialize) put together their own CDC.




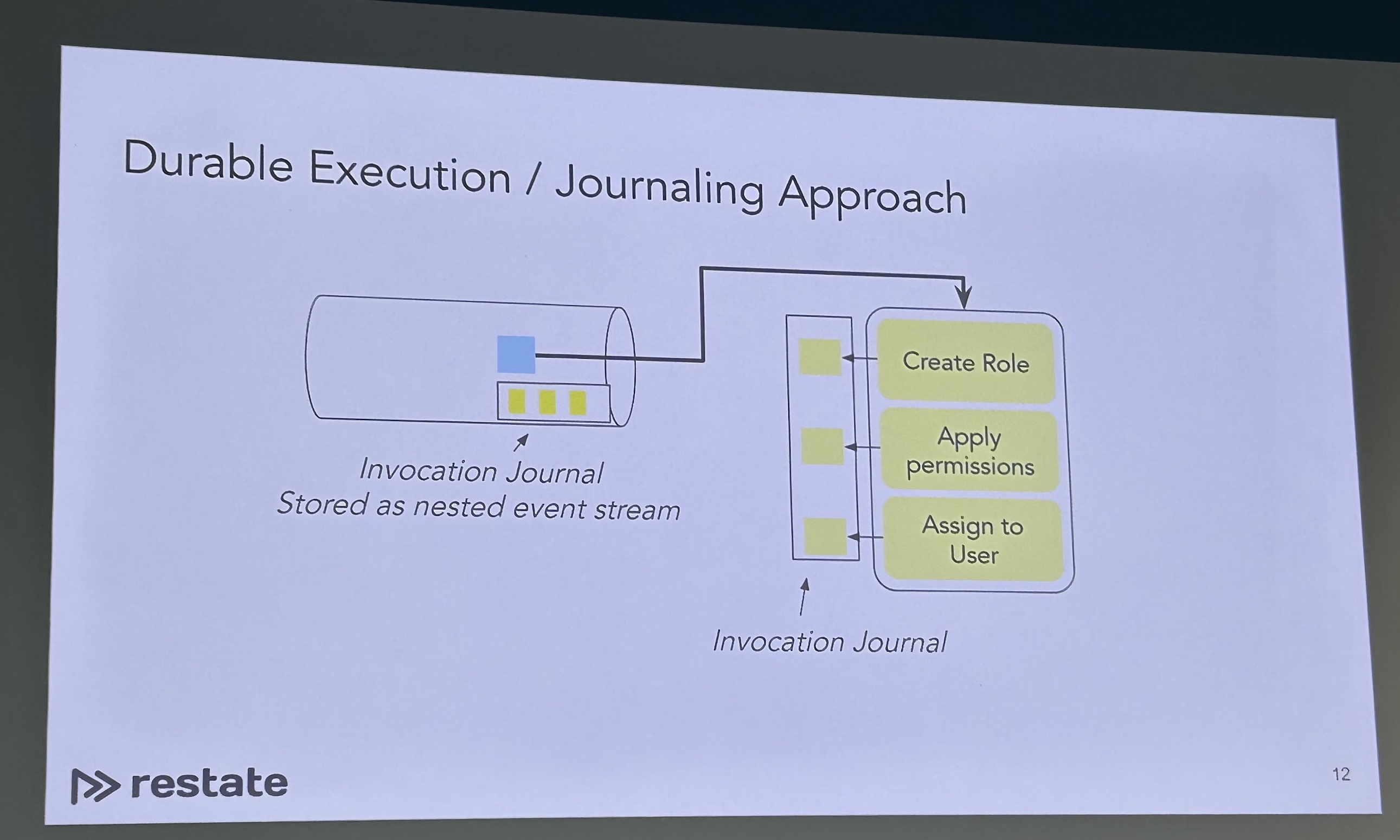
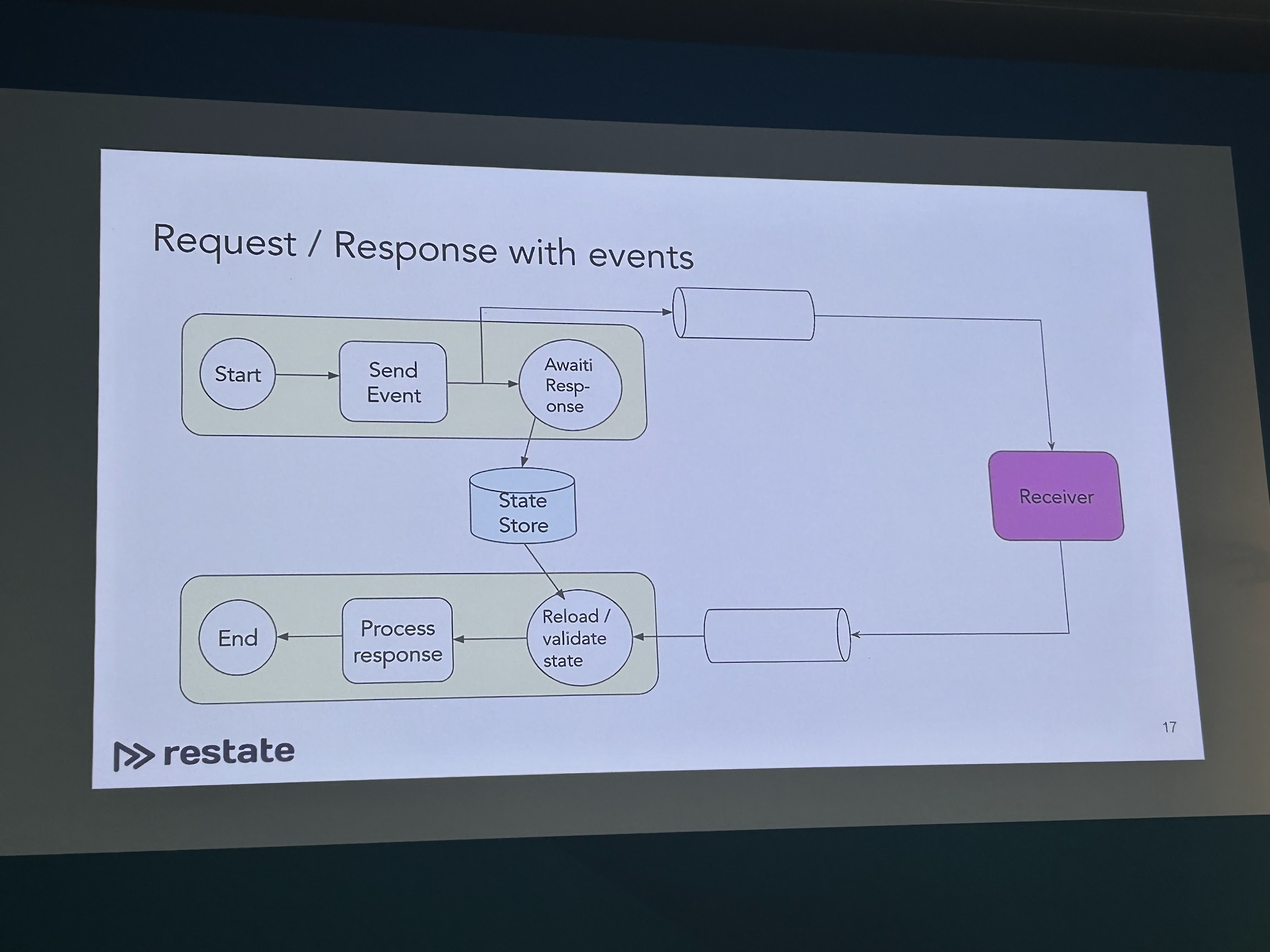
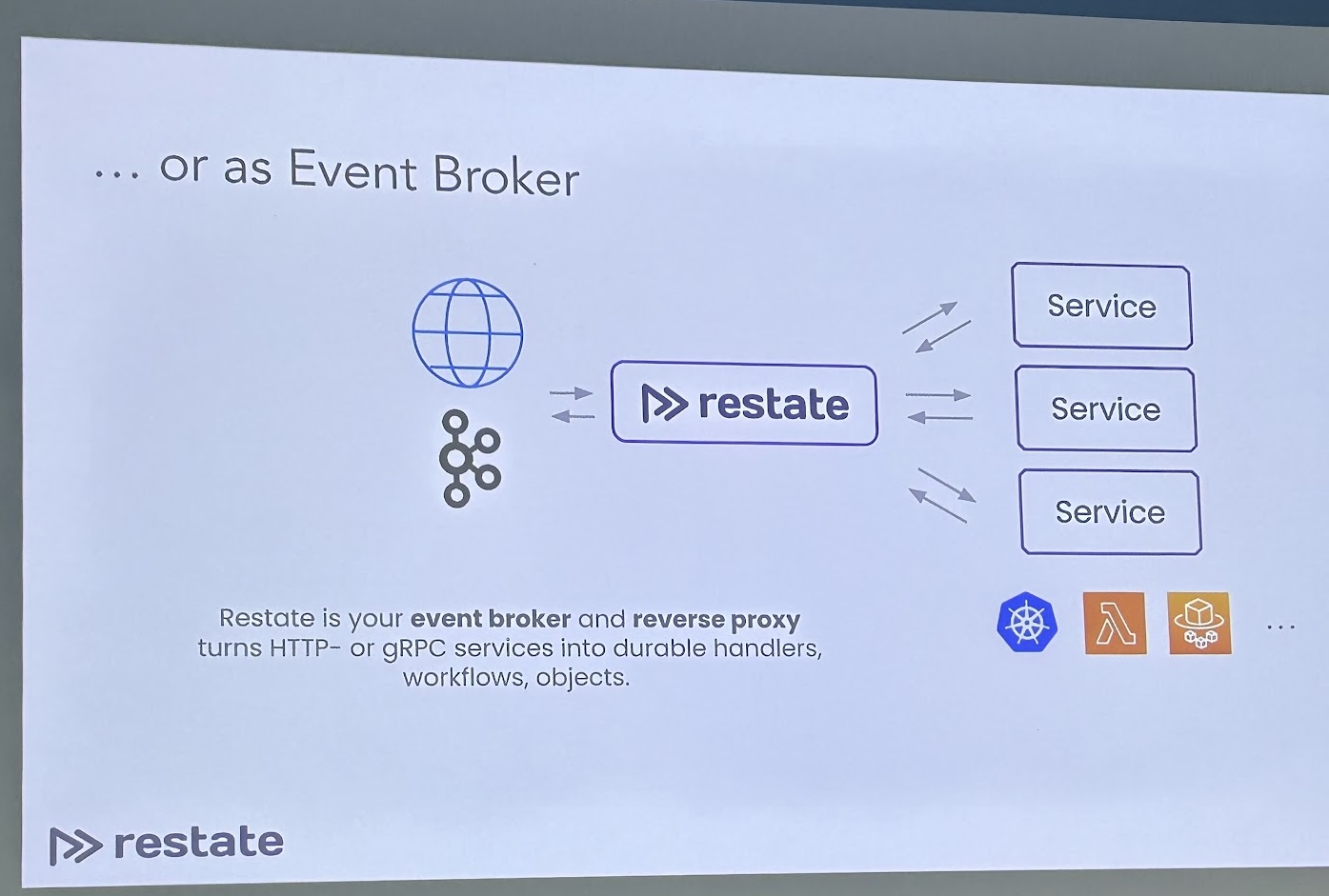
Restate by Stephan Ewen
Stephan Ewen, one of the co-creators of Apache Flink, shared about his latest project/company, Restate:
Great presentation by @StephanEwen on durable execution and how it relates to event driven stream processing—and why trying to build state machines on top of Kafka may not be the right decision. Cool stuff! #kafkasummit #ksl24 pic.twitter.com/oxmxd1EIFB
— Jorge Quilcate (@jeqo89) March 19, 2024
I have been distantly following this new application development area of “Distributed Durable Executions” or “Durable Async/Await”, mostly via Twitter; but haven’t got to dive deep into it yet. Stephan did a great job positioning his presentation for an audience that comes with a stream-processing background—given that is Kafka Summit, and Kafka Streams and Flink are widely used—and show how Restate enables the development of event-driven applications in a simpler way than what other frameworks allow.
It resonates with me given my past experiences trying to implement workflows on top of Kafka Streams—doable but a ton of work is invested in reinventing state machines on top of it. In general, found the aim to simplify the development of applications on top of Kafka quite appealing; e.g. by offering key-based partitioning to increase parallelism.
Found the deployment model of this type of engine is as a proxy to Kafka quite sensible, adding the primitives to build workflows on top.
Will keep an eye on this space with a bit more context now. Chris Riccomini shared some categorizations that may be helpful for anyone getting started:
Realized there are 4 different models for durable execution definitions:
— Chris Riccomini (@criccomini) January 30, 2024
1. UI workflow def (e.g. Camunda)
2. Config workflow def (e.g. ??)
3. Code workflow def (e.g. LittleHorse)
4. Code API (e.g. Temporal, Restate)
Seems like the first 3 can be built as libraries on (4).

Flink SQL by Robin Moffatt from Decodable
Robin’s session was perfect for people (like me) who are getting started with Apache Flink, specifically Flink SQL.
It included many time-saving tips that will help me experiment more with Flink in the future and a great demo with Flink, Iceberg, and DuckDB:
Really cool demo from @rmoff at #KafkaSummit: using Flink SQL to ingest streaming data into S3 with #ApacheIceberg as the table format, so it can be queried using #DuckDB. pic.twitter.com/GQKd7sjmDH
— Gunnar Morling 🌍 (@gunnarmorling) March 19, 2024

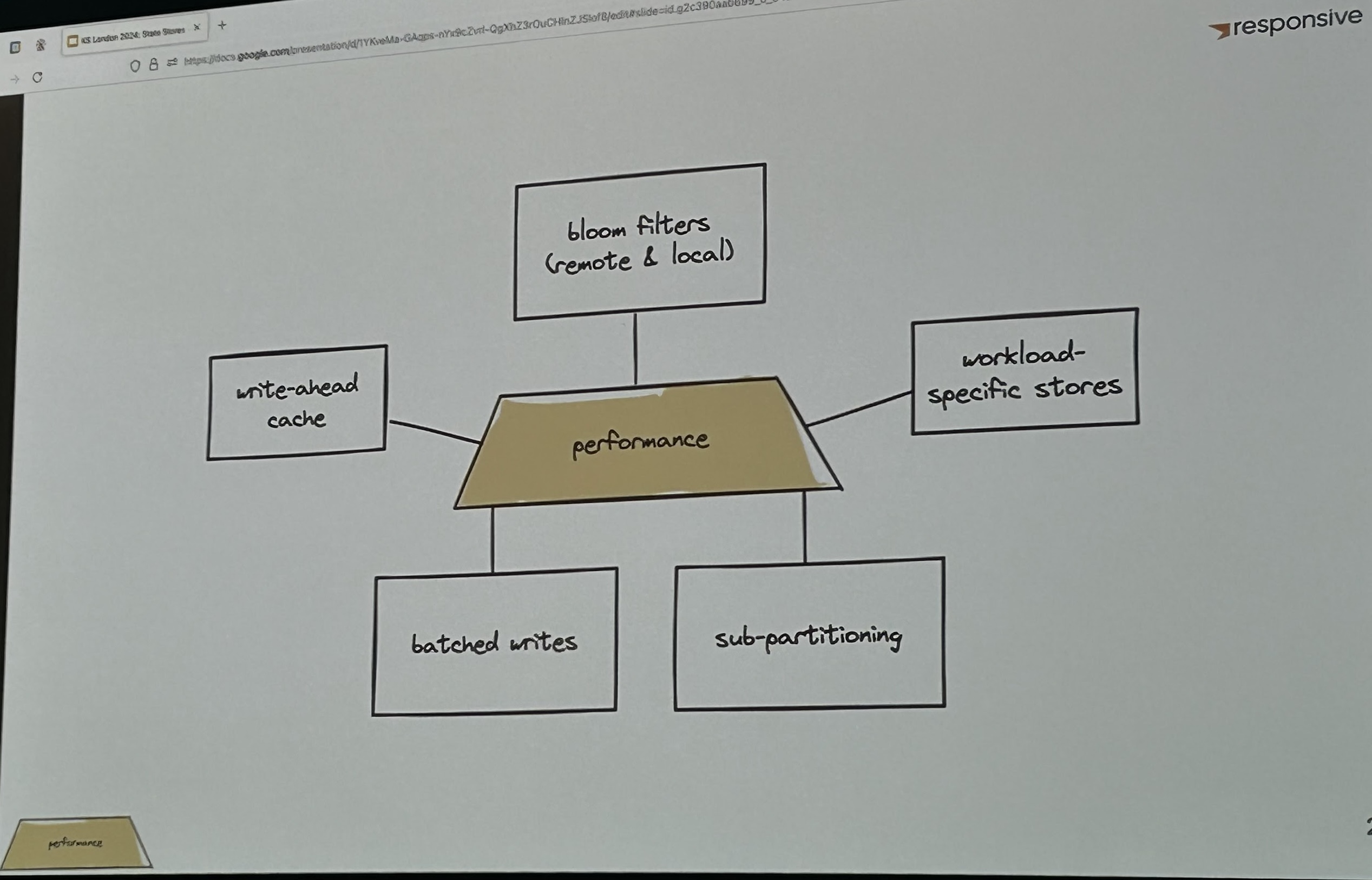
Responsive’s session on Kafka Streams State restoration with Custom State Stores
Almog and Sophie from Responsive did a deep-dive into using Custom Remote State Stores to solve restoration challenges in Kafka Streams, sharing the lessons from implementing a remote state store with MongoDB.
Responsive is moving forward many ideas around the Kafka Streams community and turning them into a reality—while sharing some of the best blog posts about Kafka Streams.
If I were still doing Kafka Streams, I’d definitely keep a close eye on Responsive.

Bo-stream-ian Rhapsody by Chris Egerton from Aiven OSPO
Chris pulled out an astonishing performance. Make sure to watch it when available.
@C0urante that was beautiful #KafkaSummit #ksl pic.twitter.com/B4qN2PVYML
— Jorge Quilcate (@jeqo89) March 19, 2024
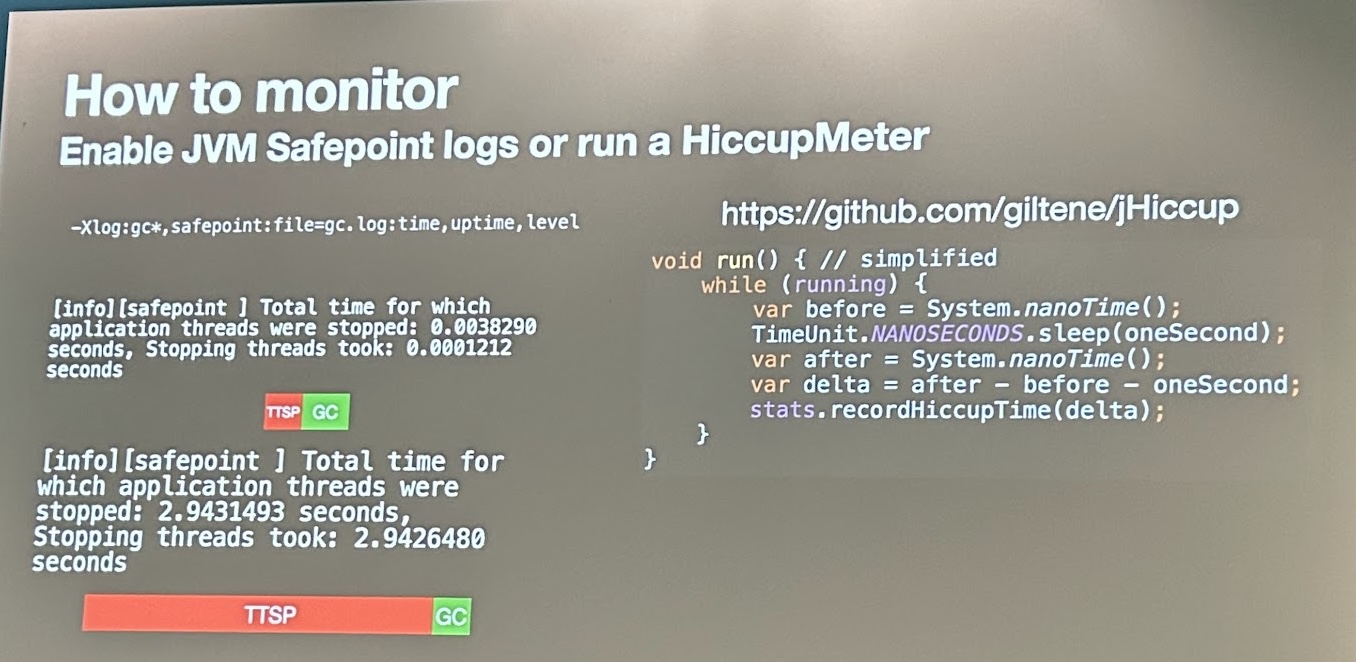
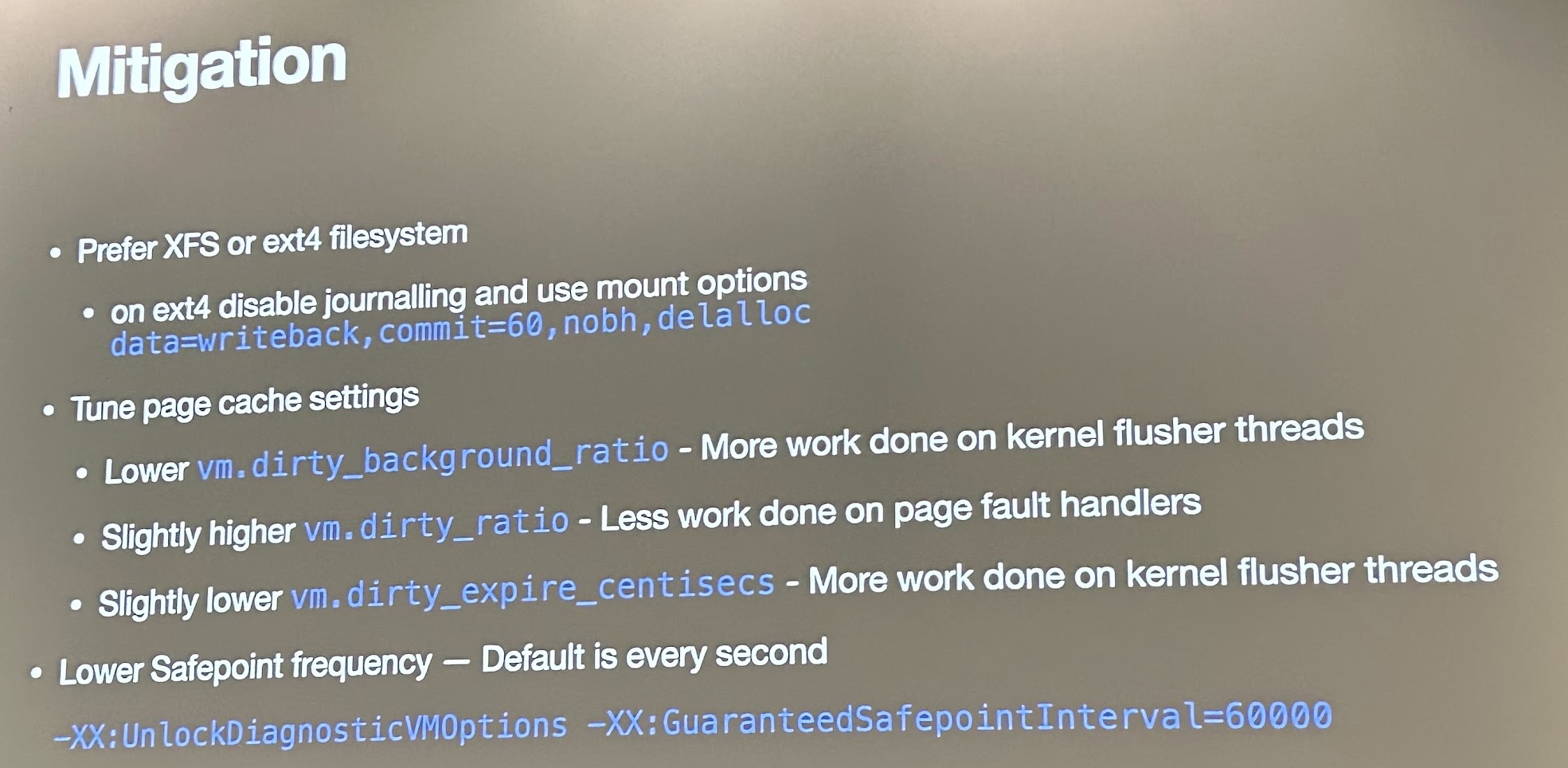
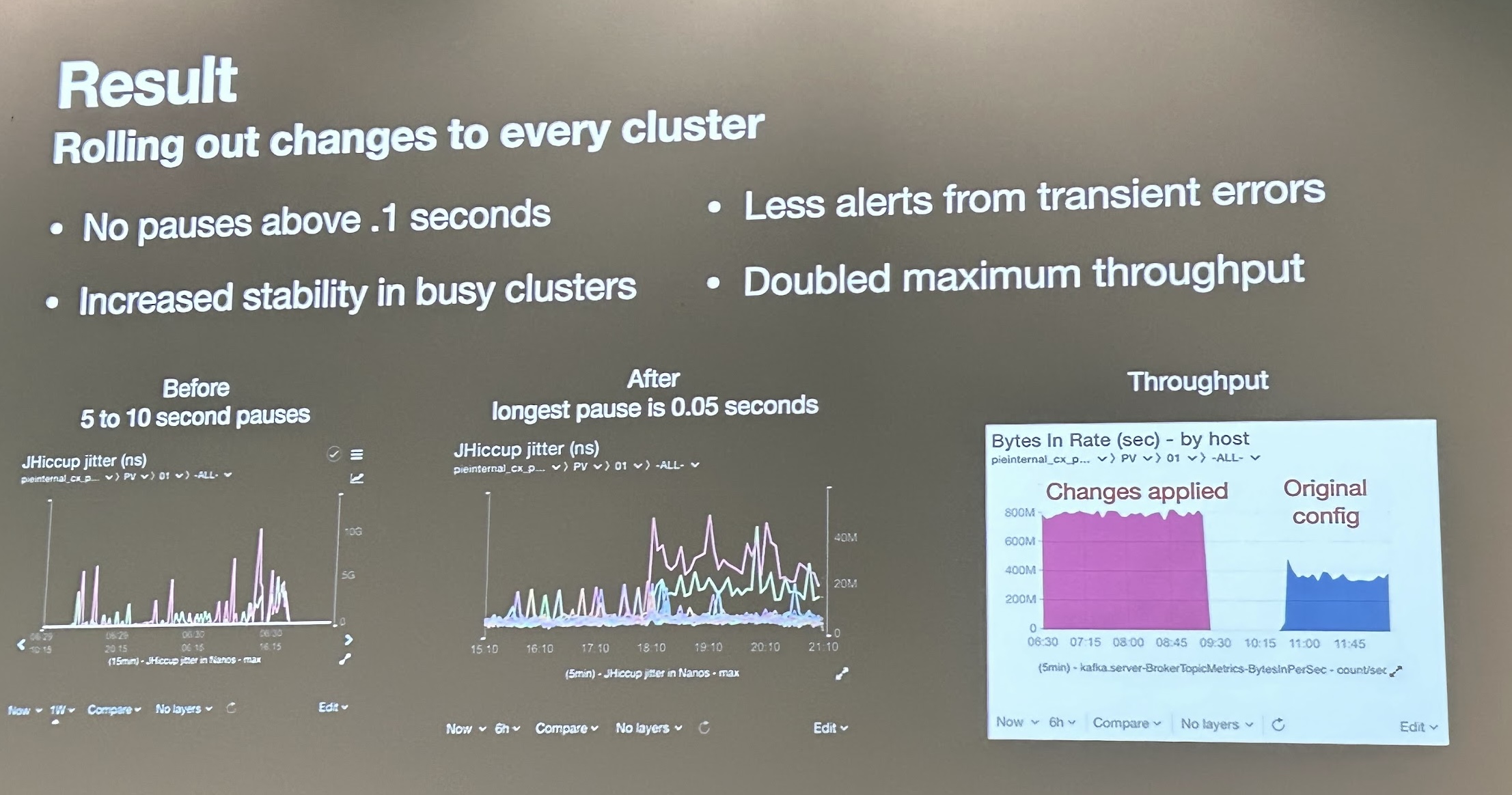
Troubleshooting JVM issues by Igor Soarez from Apple
This lightning talk (10 min.) had enough content to make it a full 45 min. session. I learned about “Time to Safepoint” (TTSP) issues on the JVM and why they are relevant to Kafka:


Kafka Tiered Storage adoption by Lixin Yao from Apple
It was quite an interesting talk for me as I have been working on Kafka Tiered Storage for the past year and have been curious about how far have Apple come with it. They seem to be on a good journey, rolling out to production earlier this year:
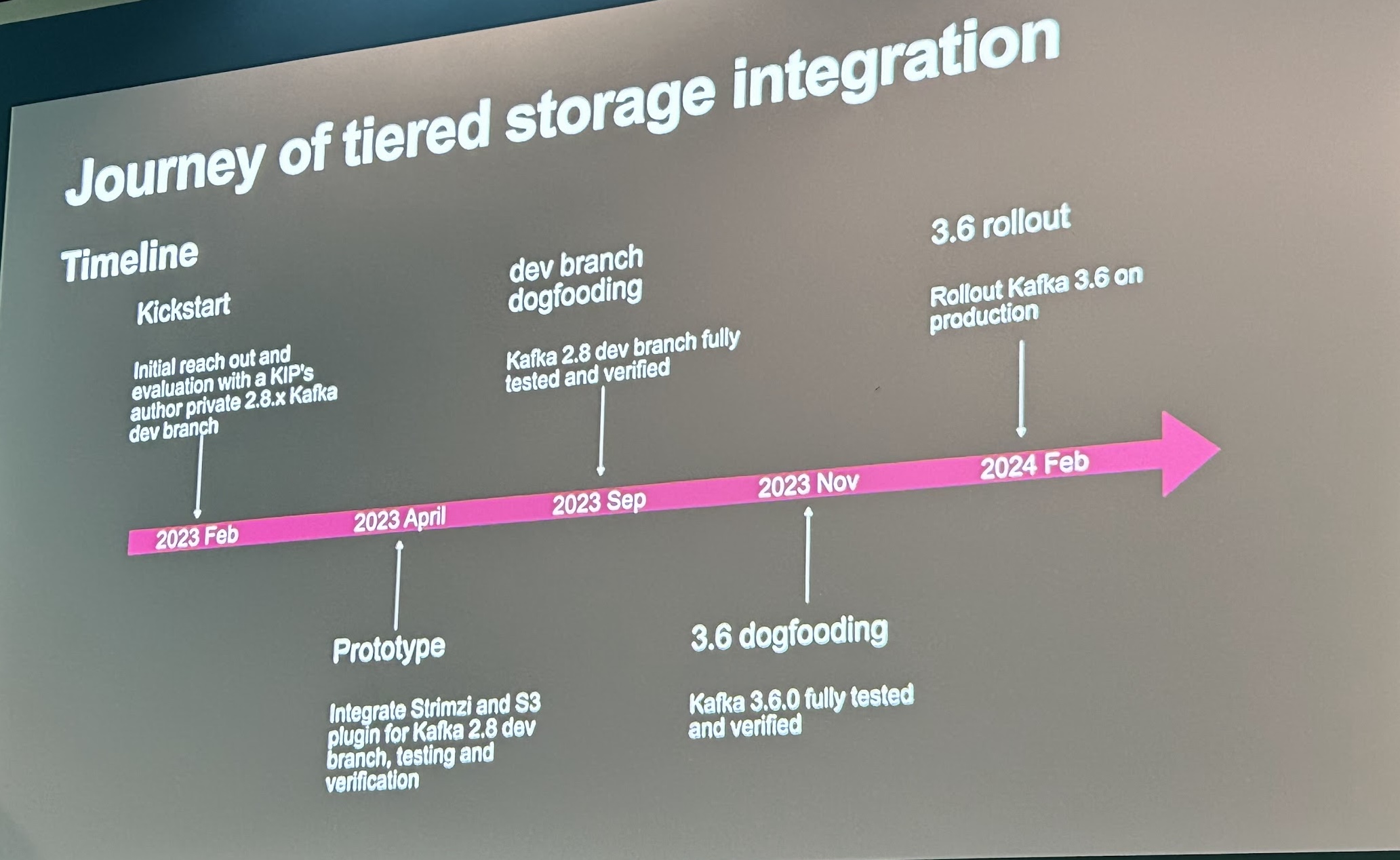

I appreciate the shout-out to the Aiven team and the feedback to improve the Kafka Tiered Storage plugin I’m contributing to.
Scaling Kafka Consumers with Olena^2 from Aiven
I had more colleagues running a session :)

Olena Babenko and Olena Kutsenko had a great dive into the challenges around scaling Kafka Consumers, reassignments, monitoring, etc. They got to a great level of detail on how reassignment works and why adding more consumer instances is not always a wise decision, why time-based lag monitoring, and the upcoming changes to the Consumer protocol e.g., KIP-848.


WarpStream by Richard Artoul
Finally, I attended the WarpStream session, where Richard Artoul (founder) introduced the platform and some of the design decisions behind taking the Kafka protocol into a no-disk journey.
This was probably one of the hottest topics in the summit: how are different companies reimagining the back-end behind the Kafka protocol; in particular, WarpStream’s proposition is quite bold on taking the most advantage of object storage’s infinite capacity and network pricing model as their key drivers:

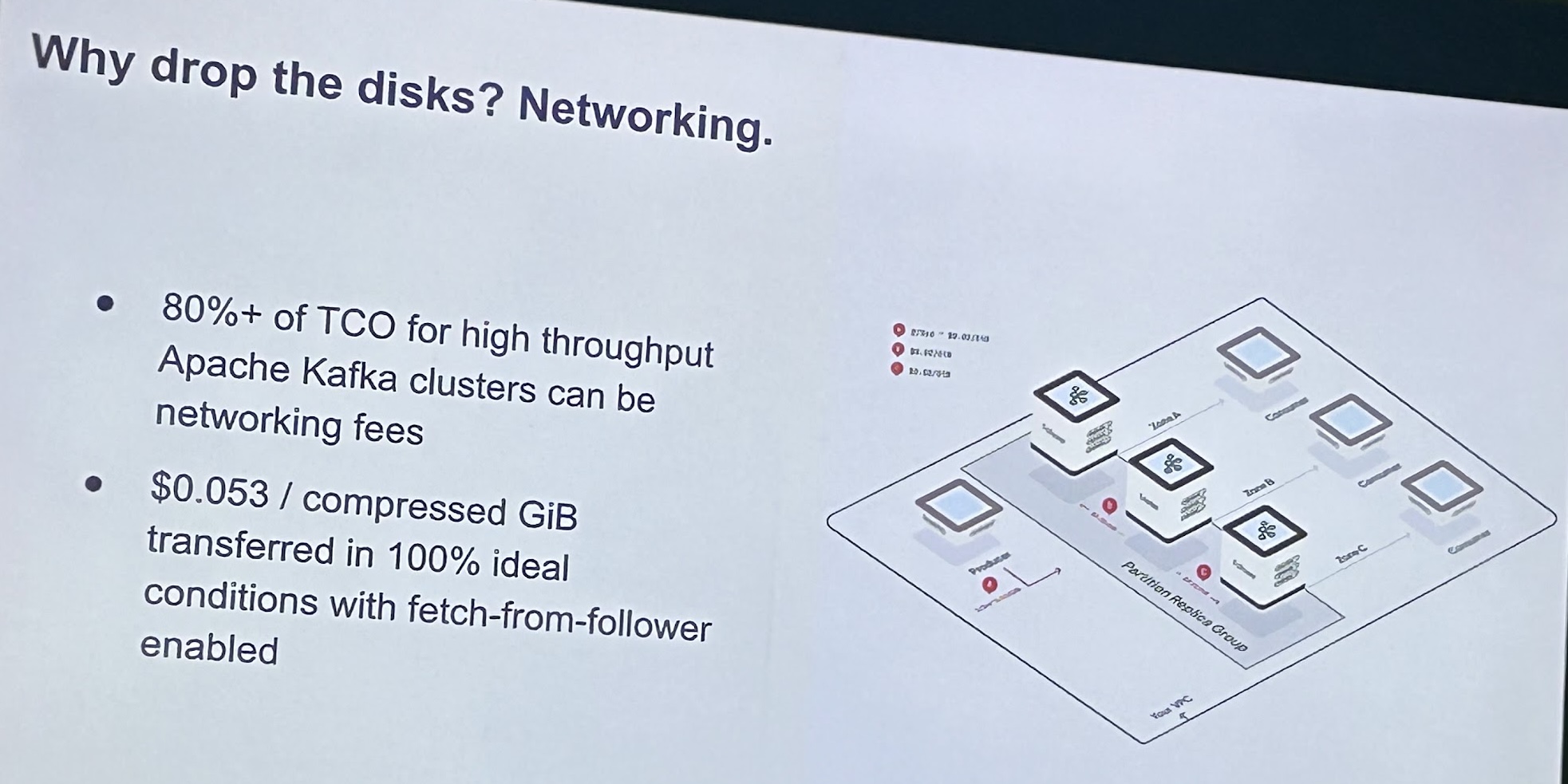

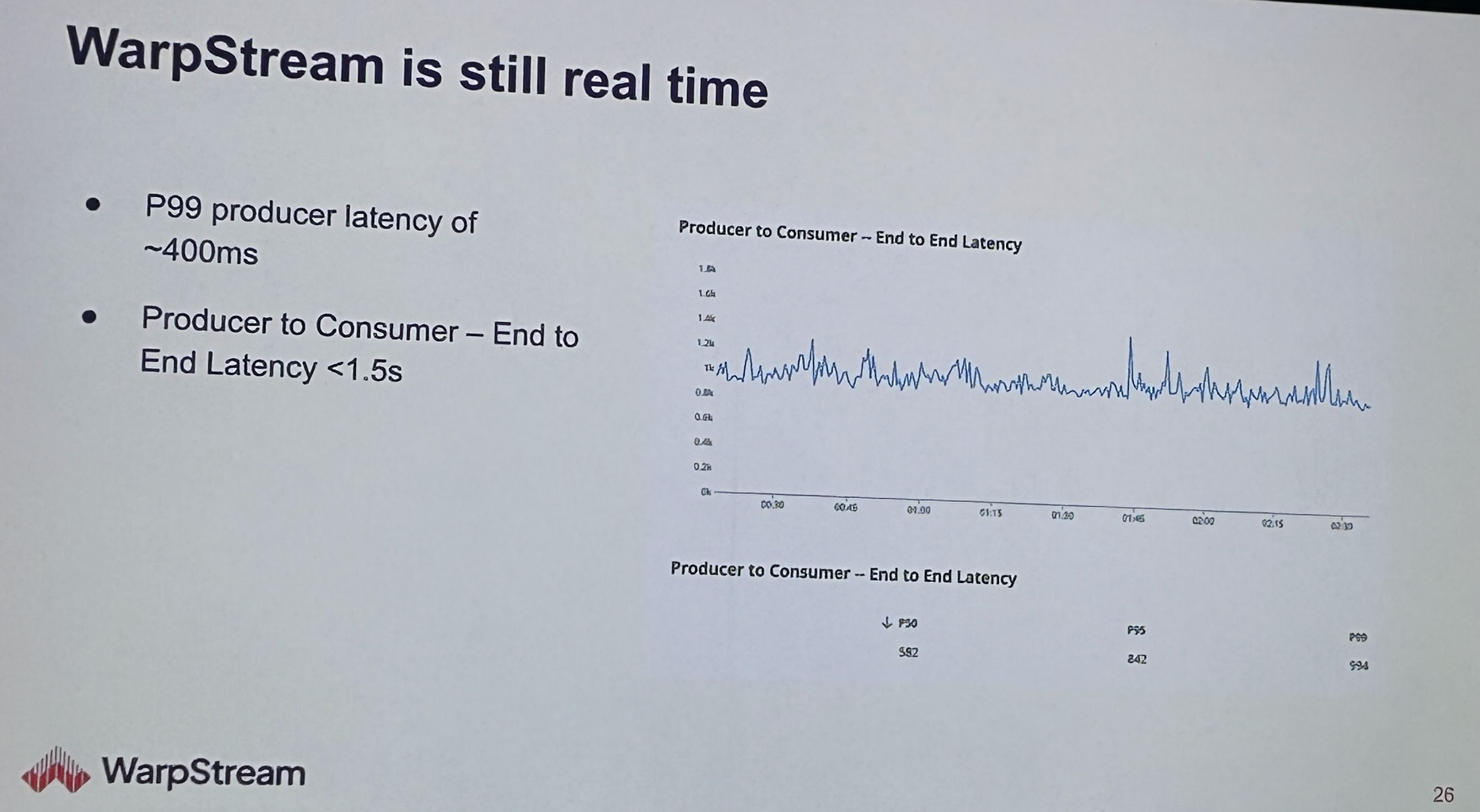
Conclusions
Overall, it was a great conference. After four years or so, it was great to be back at Kafka Summit and to attend a bunch of sessions first-hand, get to know more people in the community, and pick up some trends.
There seems to be an increasing movement on “replacing” Kafka: Confluent Kora (Cloud), Redpanda, and WarpStream. All of them in an attempt to be/stay compatible with the Kafka protocol while re-designing its backend.
Personally, I hope the OSS Kafka project and its reference implementation keep competing and staying relevant—and for the protocol to keep evolving and succeeding. KRaft and Tiered Storage (with many other advancements) are meant to be the enablers for this and are finally here to try out.
It’s an exciting and competitive area (still! even after more than a decade of being open-sourced), and I’m happy to be part of its journey.