I found this paper as relevant and accurate today as it was in 2005, when it was published. It is fascinating how even 12 years later and with new technologies in vogue, same concepts keep applying.
Overall, I found esential to evaluate concepts proposed here by Pat Helland in relation with Microservices: This paper is describing challenges that we, as developers, will have to deal when they are moving from a monolithic architecture (when we can trust that all components are located in the same context - i.e. same server), and you have to go out and face a reality where parts of your system a not any more tied to the same space and time; and methods like atomic transactions implemented by protocols like 2PC (Two-Phase Commit) are not recommended as they go against one of the goals of distribute your system that is increase your availability.
The author start explaining Service-Oriented Architecture (SOA) characteristics, currently related with Microservices:
Each service comprises a chunk of code and data that is private to that service. Services are different than the classic application living in a silo and interacting only with humans in that they are interconnected with messages to other services.
More importantly, defines implications of transaction in SOA:
To participate in an ACID transaction requires a willingness to hold database locks until the transaction coordinator decides to commit or abort the transaction. For the non-coordinator, this is a serious ceding of independence and requires a lot of trust that the coordinating system will make a decision in a timely fashion. Being constrained to hold active locks on records in the database can be devastating for the availability of a system.
Hence we can only consider atomic transactions when there is a high level of trust between components. For instance, brokers in Apache Kafka trust internally in Zookeeper service to assign a leader replica for each partition to a broker.
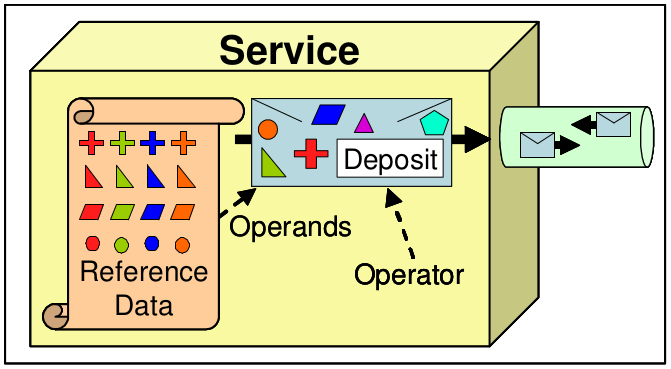
Then, a couple of concepts are introduced here that are important along the paper:
- Operators: correspond to the intended purpose for the message. Frequently, the operator reflects a business function in the domain of the service.
- Operandos: The operands are additional information required by the operator message to fully qualify the intent of the sending service. Operands are typically obtained from reference data published by a service to facilitate its later invocation with an operator message.
Data: Then and Now
This chapter details about the space/time impact of applying transactions in SOA.
When we are inside service boundaries, transactions are serializable and they give us the illusion about a unique “now”.
Transactional serializability makes you feel alone.
We can asume that two concurrent operations that we are executing: one precedes another one, one follows another one, or both are completely independent.
But once we are out of a service things change completely:
The contents of a message are always from the past! They are never from “now”
There is no simultaneity at a distance!
- Similar to the speed of light bounding information
- By the time you see a distant object, it may have changed!
- By the time you see a message, the data may have changed!
Services, transactions, and locks bound simultaneity!
- Inside a transaction, things are simultaneous
- Simultaneity exists only inside a transaction!
- Simultaneity exists only inside a service!
And then shoots:
Going to SOA is like going from Newton’s physics to Einstein’s physics.
- Newton’s time marched forward uniformly with instant knowledge at a distance.
- Before SOA, distributed computing strove to make many systems look like one with RPC, 2PC, etc.
- In Einstein’s universe, everything is relative to one’s perspective.
- SOA has “now” inside and the “past” arriving in messages.
I believe this quote is key to consider when we are evaluating migrate from a monolithic architecture into a distributed one, like Microservice: The benefits have to be bigger than the complexity that involves to work based on different laws. Just like learning and applying Einstein laws once we are used to Newton’s laws.
As Adrian Colyer describes on his paper review:
Perhaps we should rename the “extract microservice” refactoring operation to “change model of time and space” ;).
The responsability of dealing between the present inside a service, and the past that comes from the outside world is from the service application logic itself (i.e. it is a developer responsability)
The world is no longer flat!
- SOA is recognizing that there is more than one computer working together!
- Multiple machines mean multiple time domains.
- Multiple time domains mandate we cope with ambiguity to allow coexistence, cooperation, and joint work.
Data on the Outside: Immutability
When we are out of service boundaries, data (that comes as part of messages) must be immutable. This means that messages should be the same no matter when or where we do a reference.
In this part the author make important recommendations about how to identify records in SOA:
Immutability isn’t enough to ensure a lack of confusion. The interpretation of the contents of the data must be unambiguous. Stable data has an unambiguous and unchanging interpretation across space and time.
Also records should be identified not only by a version independent identifier but also by a version-dependent identifier.
To bind a version independent identifier, to the underlying data, it is necessary to first convert to a version dependent identifier.
The idea here is to be able to reference data that does not change depending on the current status. for instance: When you are processing a check-out in an e-commerce platform, products bought have a price at the time you are buying them. If your receipt does not reference a product based on a version-dependent identifier, it will reference a current version of the product, affecting the total amount.
Data on the Outside: Reference Data
This is one of the most important ponts from my point of view, because here is where most of the challenges are: How to share information that my service owns in a way that othere services can consume it in an efficient/consistent way?
In this chapter the author goes deeper about the importance of version dependent/independent identifiers and defines three uses of Reference Data:
- Operands contain information published by a service in anticipation that hopefully another service will submit an operator using these values.
- Historic Artifacts describe what happened in the past within the confines of the sending service.
- Shared Collections contain information that is held in common across a set of related services that gradually evolves over time. One service is the custodian and manages the application of changes to a part of the collection. The other services use somewhat old versions of the information.
For more information about how to deal with this challenges, Ben Stopford have written a post about how to deal with this dichotomy between services trying to encapsulate data, and data systems trying to expose it: https://www.confluent.io/blog/data-dichotomy-rethinking-the-way-we-treat-data-and-services/
Data on the Inside
After analyzing the impact of data out of the service boundaries, there is a review about characteristics of data inside a service, taking SQL as the most common way to access it:
SQL and DDL live in the “Now”
Each transaction is meaningful only within the context of the schema defined by the preceding transactions.
This notion of “now” is the temporal domain of the service comprising the service’s logic and its data contained in this database
But most importantly, the considerations about how to treat incoming messages (i.e. how to store requests from other services).
Many times, an incoming message kept as an exact binary copy for auditing and non-repudiation while still converting the contents to a form easier to use within the service itself.
I found this technique could be related with how deal with commands in an Event Sourcing/CQRS approach. For instance, Capital One has an reference implementation that consider storing commands as part of the architecture: https://github.com/capitalone/cqrs-manager-for-distributed-reactive-services
Representations of Data
XML and SQL are discussed and compared as two approaches to represent data, where XML extensibility and SQL relational capabilities are key depending on the context that they are used (inside or outside of a service):
It is this combination of hierarchy, explicit and well defined identifiers (URIs), clear mechanism for leveraging old schema within the new schema, and extensibility that has given XML its prominence in representing outside data.
SQL is clearly the leader as a representation for inside data.
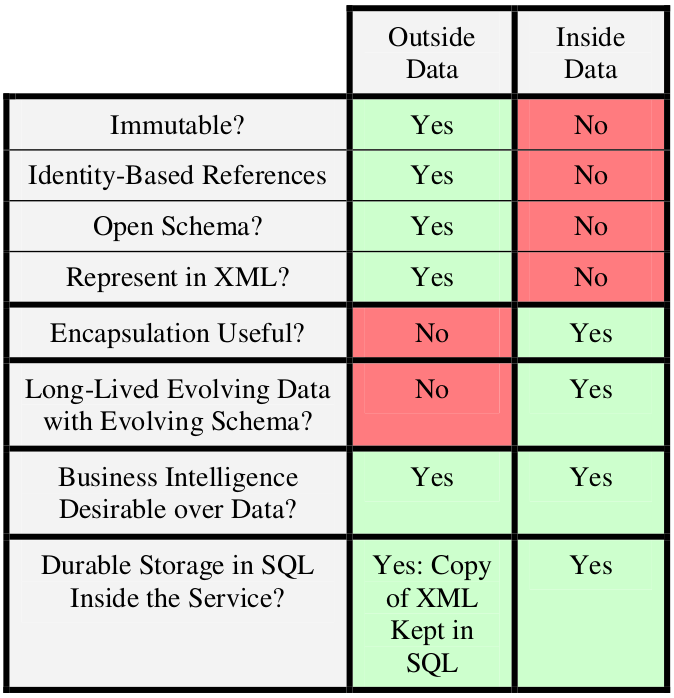
Actually we can translate similar benefits and weaknesses to other ways to represent data like JSON for outside and NoSQL database technologies for inside data
And finally compares strengths and weaknesses from three ways of representing data: XML, SQL and Objects.
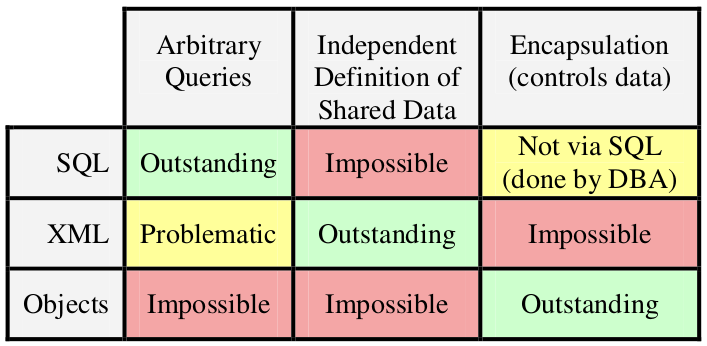
Concluding:
We simply need all three of these representations and we need to use them in a fashion that plays to their respective strengths!
References
- Link: cidrdb.org/cidr2005/papers/P12.pdf
- Author: Pat Helland
- Year: 2005