Encuentro este paper tan relevante y preciso hoy como lo fue en 2005, cuando fue publicado. Es fascinante como luego de 12 años y con nuevas tecnologías en voga, los mismos conceptos siguen aplicando.
Sobre todo encuentro esencial evaluar los conceptos propuestos por Pat Helland en relación a Microservicios: En este paper se describen los retos que afrontan los desarrolladores cuando salen de un entorno monolítico (donde se puede confiar en que todos los componentes están ubicados en un mismo entorno - i.e. un mismo servidor), y se tienen que enfrentar a una realidad donde ya no se puede confiar en que todos las partes del sistema están en mismo espacio/tiempo; y métodos como transacciones atómicas, implementado por protocolos como two-phase commit, no son recomendables ya que atentan directamente contra uno de los objetivos de distribuir componentes, que es aumentar la disponibilidad.
El autor inicia su sustentación introduciendo las características de una Arquitectura Orientada a Servicios (SOA), actualmente relevante a Arquitecturas de Microservicios:
“Cada servicio esta compuesto de una cantidad de código y datos que son privados para ese servicio. Estos servicios son diferentes a las aplicaciones clasicas, que viven en un silo y interactuan solo con humanos, en que se interconectan a través de mensajes con otros servicios.”
Más importante, define las implicancias de Transacciones en SOA:
“Para participar en una transacción ACID require que los participantes esten dispuestos a mantener bloqueados registros en la base de datos hasta que el coordinador de transacciones decida confirmar o abortar la transacción. Para los componentes independientes, este es ceder seriamente sus niveles de independencia y require mucha confianza de que el sistema coordinador va a realizar esa decisión a tiempo. Estar restringido a mantener bloqueos activos sobre registros en la base de datos puede ser devastador para la disponibiilidad del sistema”
Por lo tanto, solo se deberían considerar transacciones atómicas solo entre componentes que tienen un alto nivel de confianza, por ejemplo: brokers de Kafka confian internamente en el servicio de Zookeeper para asignar la réplica líder de una partición.
Luego, introduce 2 conceptos importantes a lo largo del paper:
- Operadores: corresponde a la intención del mensaje. Frecuentemente, el operador refleja una función de negocio en el dominio del servicio.
- Operandos: Mensajes pueden contener operandos para los operadores. Los operandos son información adicional requeridos por el mensaje operador para calificar la intensión del servicio. Operandos son usualmente obtenidos a partir de Datos de Referencia publicados por un servico para facilitar su invocación más adelante.
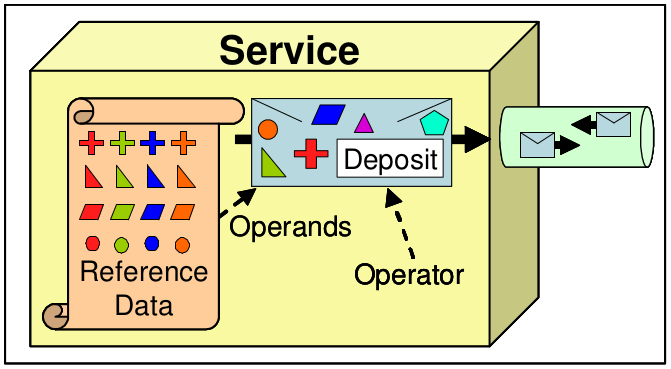
Data: Then and Now
Este capítulo va más a detalle sobre el impacto en espacio/tiempo de aplicar transacciones en SOA.
Cuando uno se encuentra dentro de los límites de un servicio las transacciones son serializables y nos dan la ilusión de que estamos en un “ahora”.
“La Serializabilidad transaccional te hacen sentir solo”
Podemos asumir que dos operaciones concurrentes que estemos ejecutando: una precede a otra, una sigue a otra, o son completamente independientes.
Pero una vez que salimos de los límites de un servicio las cosas cambian completamente:
“Los contenidos de un mensaje (e.g. request o response) son siempre del pasado! Nunca son de ‘ahora’.”
“No existe simultaneidad a la distancia!
- Similar a la velocidad de la luz que limita la informacion
- Al momento que uno ve un objeto a la distancia, puede haber cambiado!
- Al momento que uno ve un mensaje, sus datos pueden haber cambiado!”
“Servicios, transacciones, y bloqueos estan limitados por la simultaneidad
- Dentro de una transacción, las cosas son simultaneas
- La simultaneidad solo existe dentro de una transaccion!
- La simultaneidad solo existe dentro de un servicio!”
“Cada servicio tiene su propia perspectiva”
Y luego remata con la siguiente comparación:
“Moverse hacia SOA es como ir de la física de Newton a la física de Einstein
Con Newton el tiempo marcha hacia adelante, uniformemente, con conocimiento instantaneo a la distancia.
Antes de SOA, la computación distruida se esforzaba en hacer que varios sistemas aparenten ser uno con RPC, 2PC, etc.
En el universo de Einstein, todo es relativo a la perspectiva de cada uno.
SOA tiene un “ahora” dentro de cada servicio y el “pasado” arrivando a través de mensajes”
Esta cita me parece clave considerar cuando se esta evaluando migrar de una arquitectura monolítica a una distribuida, como Microservicios: Los beneficios tienen que ser mayores a la complejidad que implica trabajar en base a leyes distintas, como aprender las teorías de Einstein luego de estar acostumbrado a las leyes de Newton.
Como Adrian Colyer describe en su revisión del paper:
Quizás debamos renombrar la operacion de refactorización “extraer microservicios” a “cambiar el modelo de espacio y timepo” ;).
La responsabilidad de lidiar el presente dentro de un servicio y el pasado (o futuro dependiendo del punto de vista) que llega a través de mensajes es de la logica de aplicación del mismo servicio (i.e. es responsabilidad del desarrollador)
“El mundo ya no es más plano!
- SOA reconoce que hay más de una computadora trabajando juntas!
- Varias máquinas significa varios dominios de tiempo.
- Varios dominios de tiempo significa que nosotros debemos lidiar con la ambigüedad para permitir la coexistencia, cooperación, y trabajo conjunto.
Data on the Outside: Immutability
Cuando estamos fuera de un servicio, los datos (parte de los mensajes) deberían ser inmutables, esto permite que los mensajes sean los mismo sin importar cuando hacemos referencia, ni donde.
En esta parte, el autor hace importantes recomendaciones acerca de como identificar registros en una SOA:
“La inmutabilidad no es suficiente para asegurar que no habrán confusiones. La interpretaciones de los contenidos de los datos debe ser inequivoca. Datos estables no son ambigüos y su interpretación no cambian en relación al tiempo/espacio.”
Además los registros deben ser identificados tanto con un identificador independiente a la version, como con un identificador dependiente.
Para enlazarse con un identificador independiente de la versión, primero es necesario convertir hacia un identificador dependiente a la versión.
La idea general es poder referenciar información que no cambia, por ejemplo: Cuando estás realizando una compra on-line, los productos que compras tienen un precio en el tiempo en el que se ejecuta la compra. Si tu boleta no referencia al producto con un identificador relacionado a la versión, va a referencia a la “versión actual” del producto, afectando el cálculo del monto total de la compra.
Data on the Outside: Reference Data
Este es uno de los puntos más importantes desde mi punto de vista, ya que es donde mayores retos se presentan: Cómo compartir información que mi servicio es dueño de una forma eficiente y consistente para que otros servicios puedan consumir?
En este capítulo el autor ahonda más a detalle en la importancia de identificadores dependientes e independientes de una versión y define 3 usos de Datos de Referencia:
Operandos: contienen información publicada por un servicio en anticipado, que posiblemente otro servicio envie un operador con referencia a estos valores.
Artefactos Historicos: describen que paso en el pasado dentro de los confines del servicio.
Colecciones Compartidas: contien información que se mantiene como común entre un conjunto de servicios relacionados. Un servicio es el encargado de custodiar y manejar los cambios a parte de la colleción. Los otros servicios usan información un tanto atrazada.
Para mayor información acerca de como enfrentar este reto, Ben Stopford ha escrito un post acerca de como lidiar con la dicotomía entre Servicios tratando de encapsular datos y Sistemas de Datos tratando de exponerlos: https://www.confluent.io/blog/data-dichotomy-rethinking-the-way-we-treat-data-and-services/
Data on the Inside
Luego de analizar las implicancias de la gestión de datos fuera de los límites de un servicio, se hace una revisión sobre las características de datos dentro de un servicio, tomando SQL como la forma más común de acceso a datos.
SQL y DDL viven en el “ahora”
Cada transacción es significativa solo dentro del contexto del esquema definido por una transacción anterior.
Esta noción de “ahora” es en el dominio temporal del servicio, compuesto por la lógica del servicio y los datos contenidos en su base de datos.
Pero más importante aún me parece las consideraciones para almacenar la data que ingresa a los servicios (i.e. como guardar las solicitudes que recibimos desde otros servicios).
Muchas veces, un mensaje de entrada se mantiene como una copia binaria exacta para auditoría y no-repudio, mientras que su contendio se conviente a una forma más adecuada dentro del mismo servicio.
Esta técnica podría estar relacionada a como manejar “comandos” en un enfoque de Event Sourcing y CQRS. Por ejemplo, Capital One tiene una implementación de referencia que incluye el almacenamiento de los comandos como parte de su arquitectura: https://github.com/capitalone/cqrs-manager-for-distributed-reactive-services
Representations of Data
XML y SQL son discutidos como dos enfoques para representar datos, donde la extensibilidad de XML y las capacidades relacionales de SQL son claves dependiendo del context donde se utiliza (dentro o fuera de un servicio).
Es la combinación de jerarquía, identificadores explicitos y bien definidos (URIs), mecanismos claros para manejar esquemas antiguos dentro de un nuevo esquema, y la extensibilidad que le da a XML prominencia en la representacion de outside data
SQL is claramente el líder para representar inside data
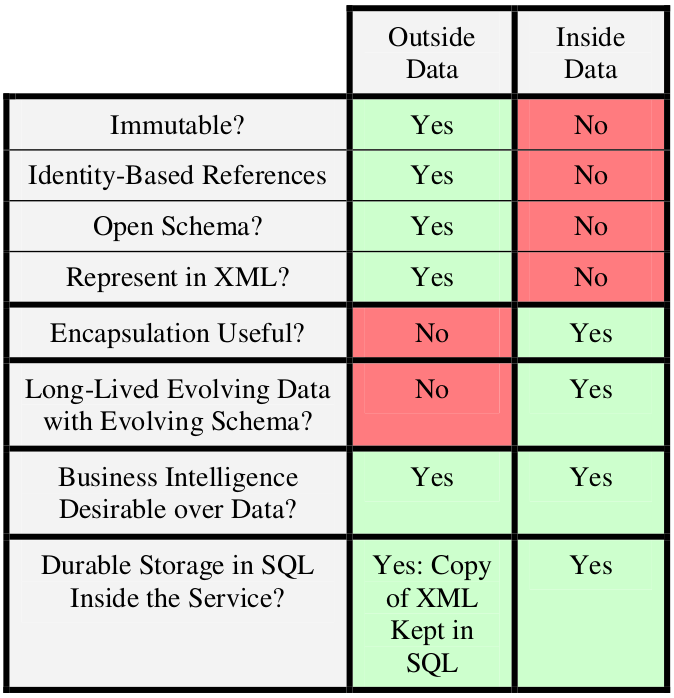
Actuamente podríamos transladar similares beneficios y debilidades a JSON como opción para datos fuera del servicio, y bases de datos NoSQL para datos internos.
Para finalmente comparar los beneficios y debilidades de 3 formas de representar datos: XML, SQL y Objectos:
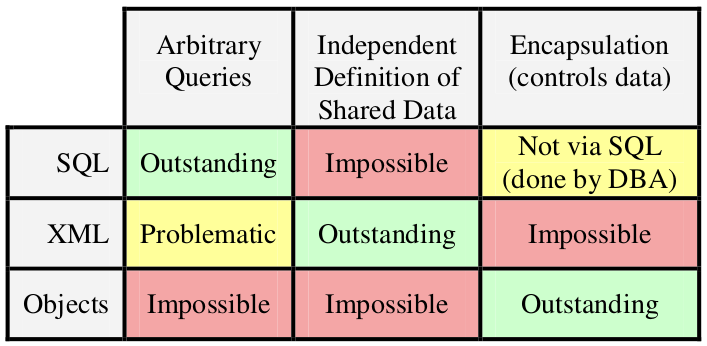
Concluyendo:
Simplemente necesitamos de los tres tipos de representaciones y necesitamos utilizarlos de una forma respectiva a sus fortalezas!
Referencias
- Link: cidrdb.org/cidr2005/papers/P12.pdf
- Autor: Pat Helland
- Año: 2005