Si bien nos podemos seguir quejando (y con muchas razones) sobre las deficiencias del Congreso, no sirve de mucho si no va de la mano de con propuestas de como apoyar a solucionarlo.
En teoría el Congreso literalmente trabaja para nosotros (los ciudadanos). Si como ciudadanos no somos capaces de entender y fiscalizar que es lo que el Congreso hace, no hay manera de controlarlos.
Sitio web del Congreso
El actual sitio web si bien tiene una apariencia renovada, la información expuesta aún no es facilmente accessible, ni procesable.
Inicialmente me he enfocado en “Proyectos de Ley”.
Tanto la búsqueda, como el listado de Proyectos de Ley, están en diferente formato que la web del congreso:

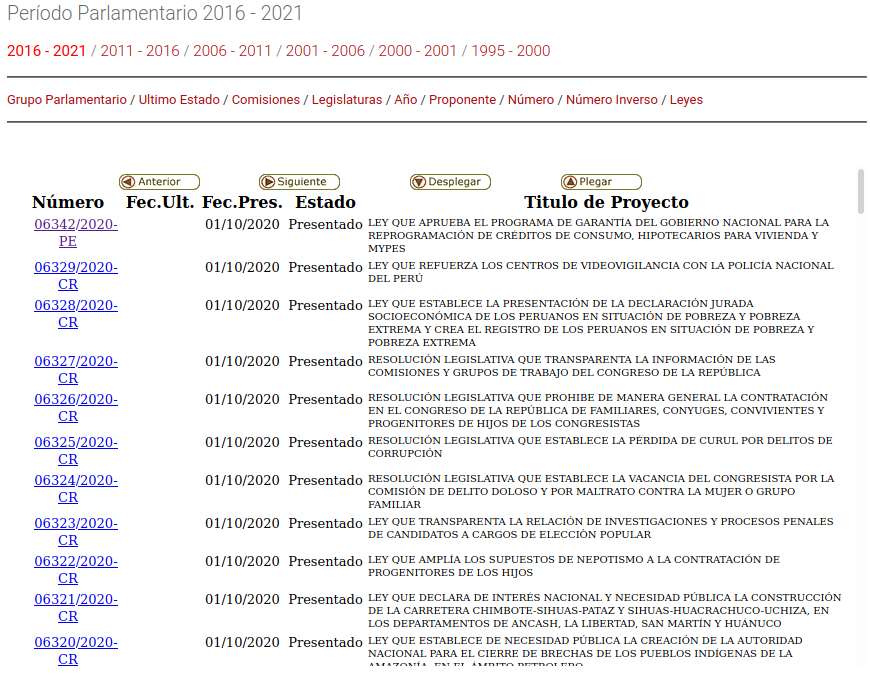
Aunque la información se encuentra disponible, no es facilmente accesible. Si bien existen enlaces, estos están “escondidos”. Por ejemplo, no existe un enlace fácil de referenciar para acceder un proyecto de ley.
Por otro lado, si se desea analizar la información de los proyectos de ley, no hay una base de datos pública que permita explotar esos datos.
Tanto la lista de proyectos, como el seguimiento y su expediente se encuentran todos en enlaces distintos.
Por último, el sitio web esta expuesto sin seguridad habilitada (HTTP).
Aunque uno puede argumentar que al brindar información pública, no es necesario encriptar los datos; pero esto no es cierto.
HTTPS es necesario para que la información sea facilmente accesible a través de motores de búsqueda como Google.
Los proyectos del ley tienen formularios que contienen información personal de los ciudadanos para publicar opiniones.
Sin HTTPS, estos datos viajan sin ser encriptados, permitiendo que esta información sea accesible en internet.
Además, si uno quiere hacer referencia a la página de un proyecto de ley a traves de <iframe>, no es actualmente posible si el sitio referenciado es HTTP.
Una de mis sorpresas fue que en realidad si existe opción para publicar opiniones sobre los proyectos de ley (!). Y por más escondida que la opción está, existen ciertos proyectos que tienen opiniones publicadas.
Con un sitio web más usable para los ciudadanos, esperaría que estas opiniones publicadas se multipliquen y podamos ejercer mayor presión sobre este poder del estado.
Política y proyectos de software
Navegando el sitio del congreso, he llegado a la conclusión de que el trabajo realizado por los congresistas no difiere tanto del trabajo de un equipo de desarrollo de software, o una comunidad open-source:
- Ambos gestionan contenido: el proyecto de software gestiona el código fuente, y el congreso gestiona el código de leyes.
- En los proyectos de software, los cambios son propuestos a través de “Pull Requests” donde un programador, o equipo de programadores, describen que cambios quieren realizar a las leyes actuales. El Congreso crea proyectos de ley que buscan implementar cambios en la Constitución u otros código de leyes.
- Las propuestas de cambio pasan por un proceso de revisión y aprovación similar a los proyectos de software.
- Los cambios en el ciclo de vida de un proyecto de ley son capturados en su seguimiento, similar a los cambios de un “issue” en JIRA u otro gestor de proyectos.
La gran diferencia es que los proyectos de software utilizan plataformas abiertas como GitHub, donde uno puede navegar todos los cambios que han pasado un proyecto, quien ha realizado los cambios, quienes lo aprobaron, etc.
Luego de revisar brevemente como funcionan los proyectos de ley en el Congreso, no me es difícil imaginar un futuro donde los proyectos de ley sean gestionados con git, publicamente accesibles, y discutidos abiertamente.
De echo, la discusión abierta es la parte más importante de un proyecto de software. Las consultas, recomendaciones, y como la propuesta se va mejorando para ser aprobada. Esto actualmente no existe, o es efímero en las sesiones del congreso. Si pudieramos tener no solo la evaluación de un proyecto ley, sino también la discución de como se llego a la versión final, sería de tremendo impacto en terminos de fiscalización y evaluación del congreso.
Para poner un ejemplo, imaginen el Congreso gestionando repositorios en GitHub:
Donde podamos acceder al estado actual de las leyes:
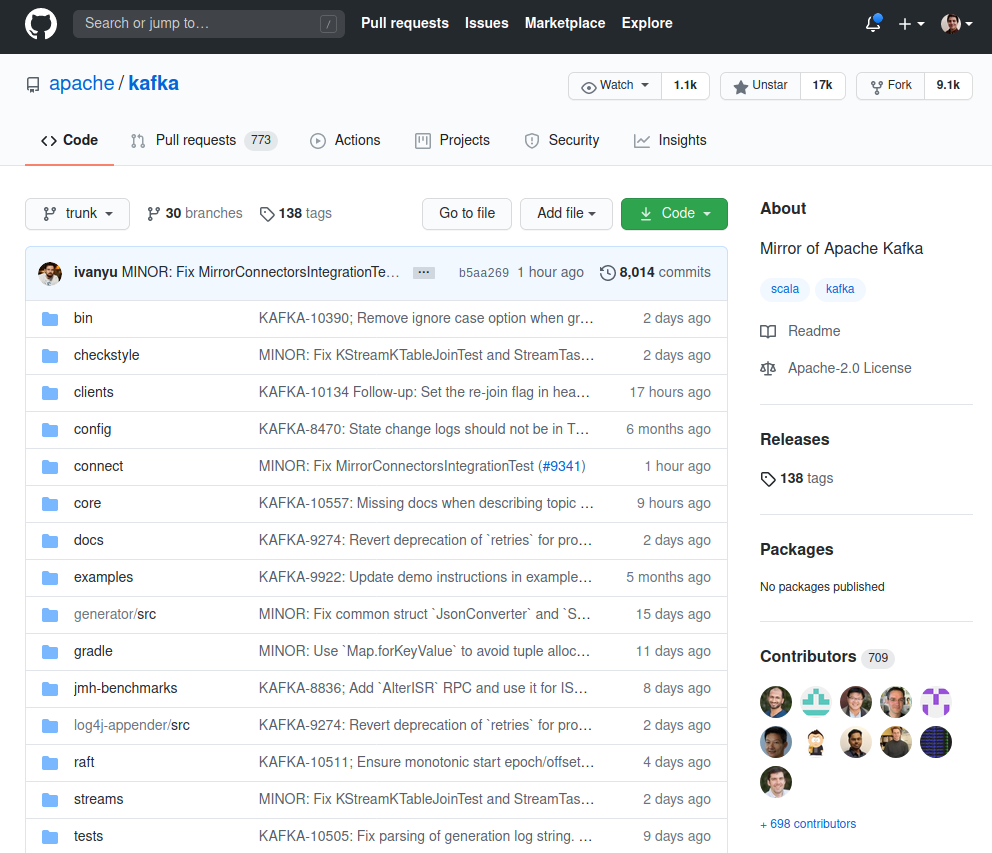
Por ejemplo, en “Contributors” en la zona derecha podriamos acceder a los Congresistas que contribuyen al proyecto, y quien es el que más contribuye, etc.
Los números de “Pull Requests” abiertos, representarían los proyectos de ley abiertos y en discusión:
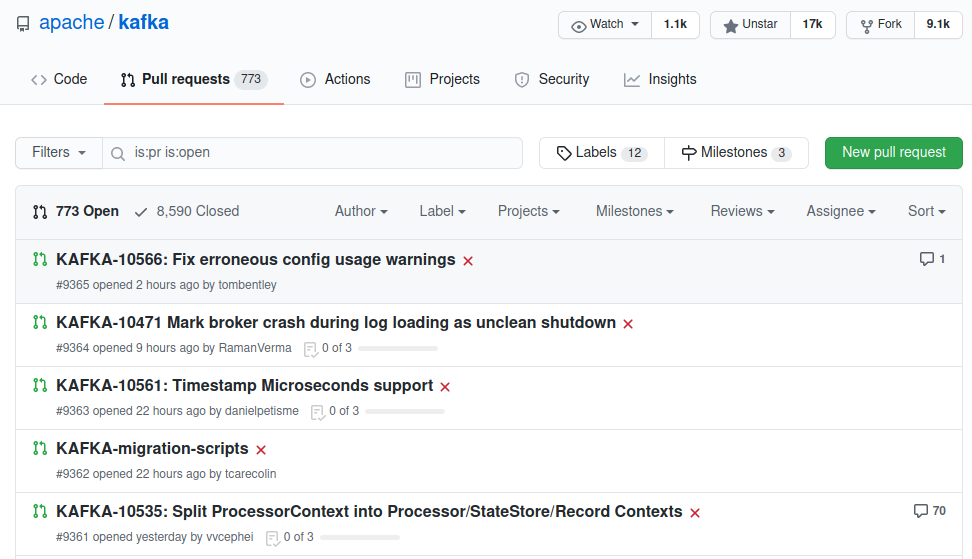
Si uno quiere revisar un proyecto de ley, revisaría un “Pull Request”, y vería la discución y los textos propuestos:
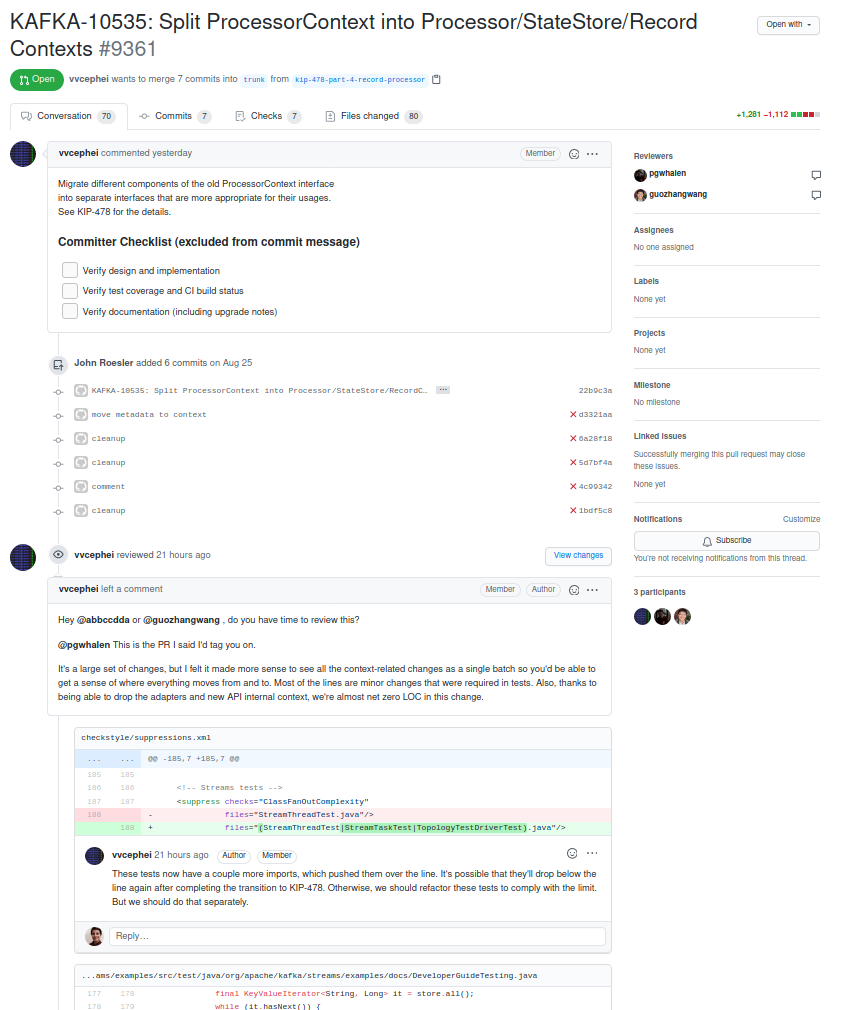
Donde en vez de código fuente de software, veríamos específicamente los cambios propuestos en las leyes. Y cualquier ciudadano podría comentar específicamente que parte apoya o propone modificar previo a la aceptación.
Obviamente, esta idea no es nueva. Me inspiré en esta charla de Ted https://www.ted.com/talks/clay_shirky_how_the_internet_will_one_day_transform_government
Experimento: nuevo sitio web para el Congreso
Si bien esta visión puede verse bastante lejana, se pueden ir experimentando algunas mejoras.
Para mejorar la referenciación y seguimiento de los proyectos, podriamos exponer los proyectos en un sitio web más simple, tipo blog, donde cada post sería un proyecto de ley.
Este proyecto de es un intento de materializar esta propuesta: https://github.com/jeqo/peru-congreso. Y el resultado es el sitio web: https://jeqo.github.io/peru-congreso
Importación de datos
El primer paso para experimentar con estos datos, es importar la información desde el sitio web del Congreso. Como no existe una base de datos pública, he tenido que acceder directamente al código disponible en el sitio web para extraer los datos de la página web HTML.
Luego de extraer los datos y los enlaces al seguimiento y expediente, he podido obtener toda la información relacionada a un proyecto de ley.
Los datos son guardados en un sistema de datos local (Apache Kafka), para ser luego procesados.
Actualmente esta importación depende directamente de la estructura de la página web. Si la web es actualizada (espero que mejorada) va a requerir modificar el proceso de importación.
Exportación de datos
Los datos importados son procesados y exportados en distintos formatos:
- CSV: https://jeqo.github.io/peru-congreso/proyectos-ley/2016-2021.csv
- Blog (usando Hugo): https://jeqo.github.io/peru-congreso
- Twitter: https://twitter.com/otrocongresope
El objetivo de exportar los datos en formato CSV es para permitir que científicos de datos puedan procesar esta información y analizar el rendimiento del Congreso.
El blog busca darle fácil acceso a los proyectos.
Y Twitter permite la publicación de actualizaciones para su discusión en esta plataforma.
Actualmente estas exportaciones son ejecutadas manualmente de forma diaria.
Para mayores detalles técnicos: aquí
Conclusiones
Este experimento funcionará hasta que el sitio del Congreso sea reemplazado. Ojalá por uno mejorado y considerando las propuestas expuestas antes.
Me atrevería incluso a exigir que tanto los datos, como el sitio web del Congreso─incluso los sistemas de gob.pe─deberían ser gestionados como proyectos de código abierto, para que sean auditables y mejorables por los ciudadanos.